Software Architecture


Software Architecture
Architecture
- Defines the programming paradigm that will be used (object orientation, functional, etc.)
- Chooses frameworks and libraries that will be the system's foundation
- Determines communication patterns between components (REST API, RPC, message queues, etc.)
- Delimits technologies that can or cannot be used
- Specifies the high-level layered architecture (presentation, business logic, data access, etc.)
Design
- Defines the responsibilities and roles of each layer and component
- Models classes, interfaces and interactions between components
- Determines design patterns to be used when applicable
- Specifies contracts and communication APIs between layers/services
- Describes essential system data flows and operations
- Designs the data model and database schema
- Handles non-functional requirements like performance, security and scalability
We spend most of our time reading code, not writing it, so good design is important.
Behavior
It's what makes stakeholders earn or save money, it's domain-related.
Structure
It's what keeps the behavior standing without collapsing. The more behavior is added to the software, the more structure will be required to effectively support it.
"There are several companies that go bankrupt with well-written software, but few succeed and thrive over time with poorly-written software."
Refactoring
"Making alterations to the internal structure of software to make it easier to understand and less costly to modify without changing its observable behavior" - Martin Fowler
When refactoring always consider clean code.
Transaction Script
Organizes most logic as a single procedure.
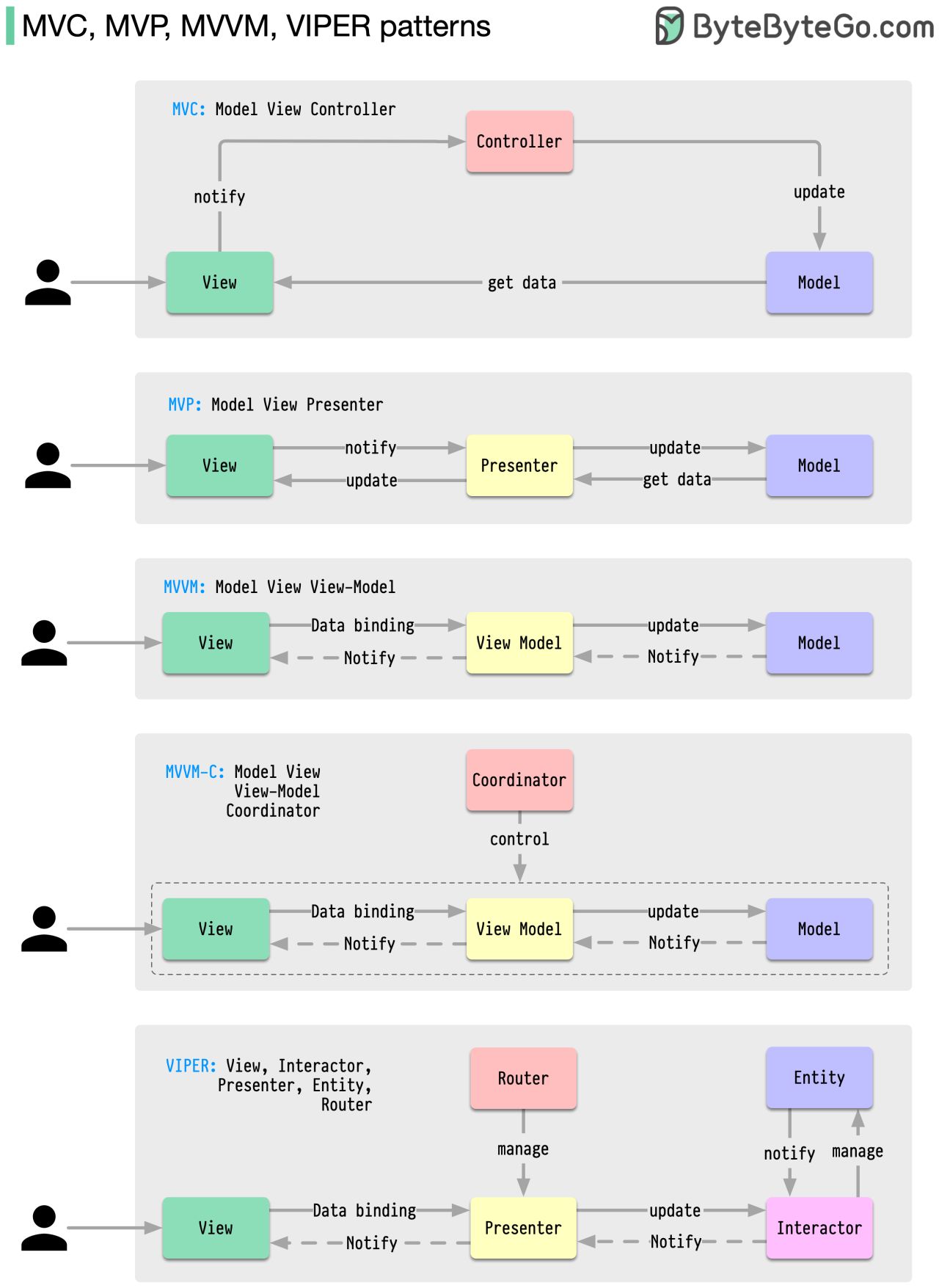
MVC, MVP, MVVM, MVVM-C, and VIPER
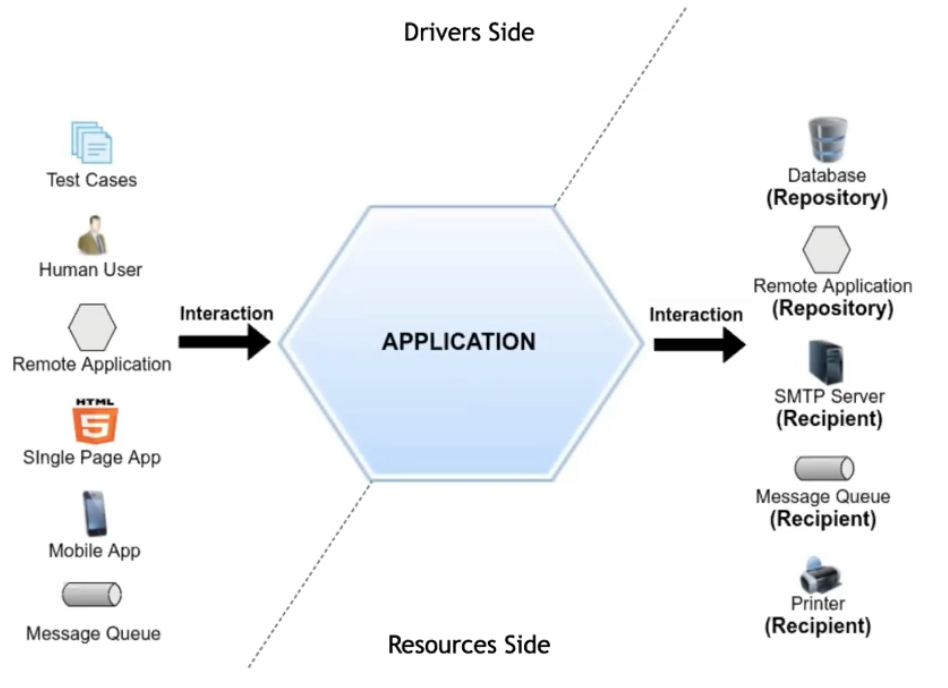
Hexagonal Architecture - Ports and Adapters
"Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases" - Alistair Cockburn
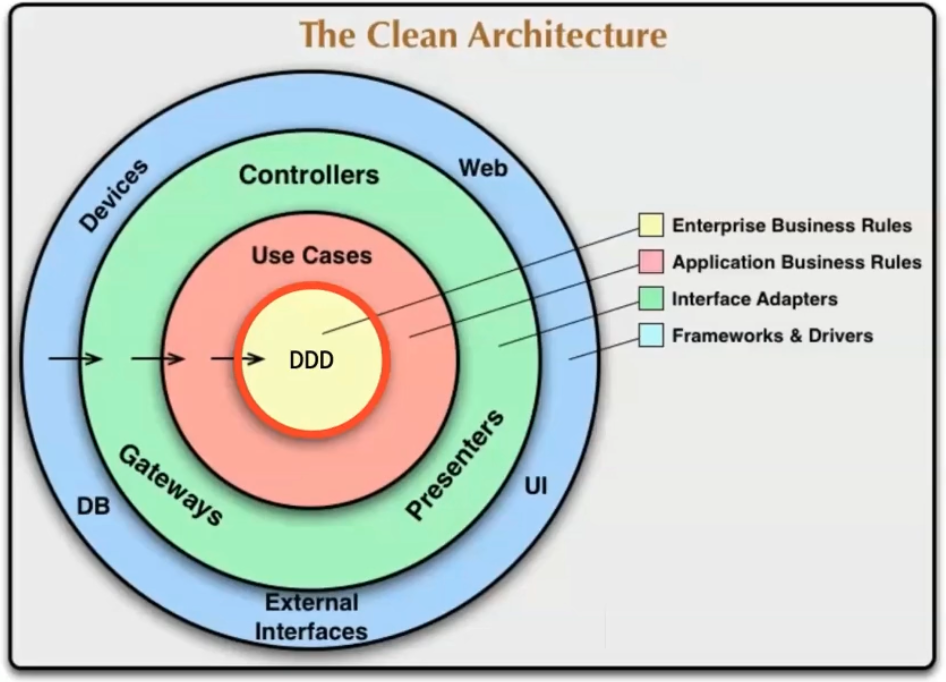
What's inside doesn't know what's outside, but what's outside knows what's inside. Entities don't know use cases and those don't know interface adapters' implementation, which don't know frameworks and drivers' implementation.
Interface Adapters
- Bridge between use cases and external resources
- HTTPS requests
- Database access (ORM or SQL)
- External API integration
- Disk reading and writing
- Data conversion to specific formats
Clean Architecture
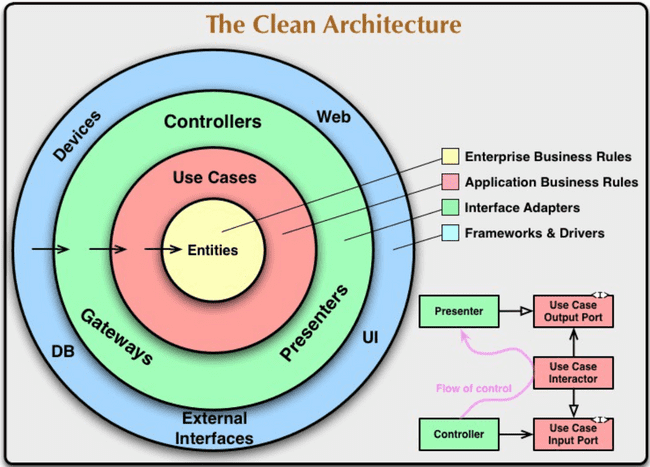
Use Cases
"The center of your application is not the database, nor is it one or more of the frameworks you may be using. The center of your application is the use cases of your application" - Robert Martin
- Orchestrate entities and external resources
- That mutate should have effects tested
- That read should have return tested
Object-Oriented Design Principles
- Encapsulation - Hide internal variations and complexities
- Cohesion - Keep related things together
- Loose Coupling - Reduce dependencies between modules
- Separation of Concerns - Divide by functionalities and specialties
Benefits of Clean Architecture
- Code easier to read and understand
- Higher team productivity long-term
- Reduces maintenance costs and adds business value
- Allows evolving software with requirements
Clean Architecture in Practice
- Start by thinking about use cases and business rules
- Apply architectural patterns when appropriate (e.g. MVC)
- Test-driven development (TDD)
- Constant refactoring as needed
- Vibrant documentation and visual models
Signs of Architectural Problems
- Too many dependencies between components
- Large and non-cohesive classes
- Brittle and code-coupled tests
- High effort to add new functionalities
Fixing Architectural Problems
- Breaking large classes and modules
- Applying SOLID principles and patterns when possible
- Introducing layers and clear separation by capabilities
- Evolving architecture with requirements
Concepts
In Patterns of Enterprise Application Architecture we have:
- Table Module: combines business rules and data access (separating components by table)
- Table Data Gateway (DAO): handle all table access in one place. A DAO becomes a repository when it knows (receives and returns) domain entities.
- DTO: Data Transfer Object - Use cases don't expose domain objects, they expose DTOs (contracts).
Main Layer
The main is the application's entry point (HTTP, CLI, UI, Tests). That's where factories and strategies are initialized and dependency injections happen during startup.
"When composing an application from many loosely coupled classes, the composition should take place as close to the application's entry point as possible. The Main method is the entry point for most application types. The Composition Root composes the object graph, which subsequently performs the actual work of the application"
Dependency Injection Containers
Useful for managing dependencies between objects and classes in an application. Some reasons to use them:
- Facilitates class decoupling - As dependencies are injected by the container, classes become loosely coupled. This allows easier modification and testing.
- Avoids manual dependency creation - The container handles instantiating classes and injecting needed dependencies. This simplifies client code using those classes.
- Allows reuse and swapping implementations - By just configuring the container, you can instruct it to use different interface implementations. This facilitates reusing and swapping code.
- Provides object lifecycle management - The container can manage when objects are created and destroyed. This is important in complex applications to free resources.
- Works well with patterns like Dependency Injection and Inversion of Control - These patterns can be more easily implemented using a container.
In short, using dependency injection containers facilitates writing more decoupled, testable code that is easier to maintain and extend. This makes up for the extra complexity of configuring and integrating it in the application.
Domain Driven Design
Complements Clean Architecture's Entities layer, which doesn't define entities. It's a domain-focused design applied to the domain layer.
Domain
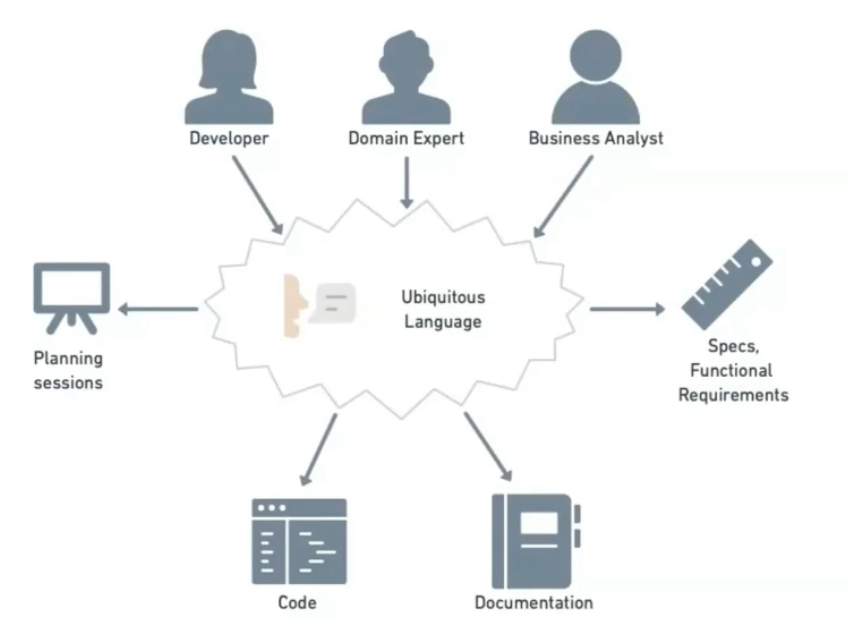
It's the business problem that needs solving independently of the technology to be used. Extracting domain knowledge is usually difficult (Product Owner, Product Manager, Clients...). The ubiquitous language unifies how the domain is talked about.
Tactical Design
Used to build the domain layer, distributing complexity across domain objects. Over time, especially in complex domains, it becomes messy with many people and integrated business areas involved. A phenomenon known as Big Ball of Mud often happens.
Domain Objects
Domain Objects vs ORM Objects
How to decompose/normalize the domain differs from how to decompose/normalize the database. In databases avoiding duplicated data through normalization is ideal. But if the system is simple, it may happen.
Entities
Objects with distinct identity that are different even with equal attributes. Goal is data mutation (behavior + data). A set of data with behavior.
Anemic Domain is data without behavior.
Generating identity
- Manually: The user generates the entity identity (e.g. email, ID document)
- Application: The app uses an algorithm like UUID generation
- Database: The database generates identity through sequences or other mechanisms
Examples: User, Product, Order.
Value Objects
Objects defined by their attribute values without distinct identity. Immutable - change implies replacement. Two value objects with equal attributes are considered equal. They also contain independent business rules. Used so Entities don't get too big and can be reused across entities.
Examples: Address, Date, Color, Dimension, Password.
TIP: Try replacing a value object with a primitive type like string or number to identify it
Domain Services
Encapsulate complex business logic related to multiple domain objects without state. Used when an operation doesn't belong to an entity or value object.
Examples: TaxCalculator, BoletoIssuer
TIP: Don't create services instead of entities and value objects, favoring an anemic model
Factories
Encapsulate complex domain object creation, centralizing knowledge on how to create them.
Aggregates
A cluster of domain objects like entities and value objects establishing relationships between them. A consistent group of domain objects treated as one unit. Ensure transactional consistency.
TIPS:
- Can an aggregate reference other aggregates? Yes, but by identity
- Can an aggregate have just one entity? Yes, smaller is better
- Can an entity belonging to one aggregate belong to another? Doesn't make much sense as changes could break the other
Repositories
Abstract and encapsulate the persistence layer, providing a simple interface for saving and retrieving domain objects. Goal is serving the domain. Shouldn't be used for client-specific data visibility. It translates external relational objects (DB, APIs) to domain objects. For client-specific data use CQRS.
Strategic Design
Strategic Design is how to divide the domain. It identifies and defines boundaries between bounded contexts. Every domain can and should be divided into subdomains.
Subdomain Types
- Core: Most important, drives business value, where you put your best efforts
- Supporting: Complements the Core without which business success isn't possible
- Generic: Can be delegated to other companies or be an off-the-shelf product
Bounded Contexts
A bounded context represents a conceptual boundary around a domain or subdomain. Within that boundary, a domain model is valid and applicable. Outside that boundary, the model doesn't apply. Think of it as a business modularization form to reduce internal code coupling (Big Ball of Mud).
Each bounded context has its own:
- Domain model (entities, values, business rules, etc)
- Ubiquitous Language
- Specific implementations
Relationships
Bounded contexts interact through carefully managed relationships. Some types:
-
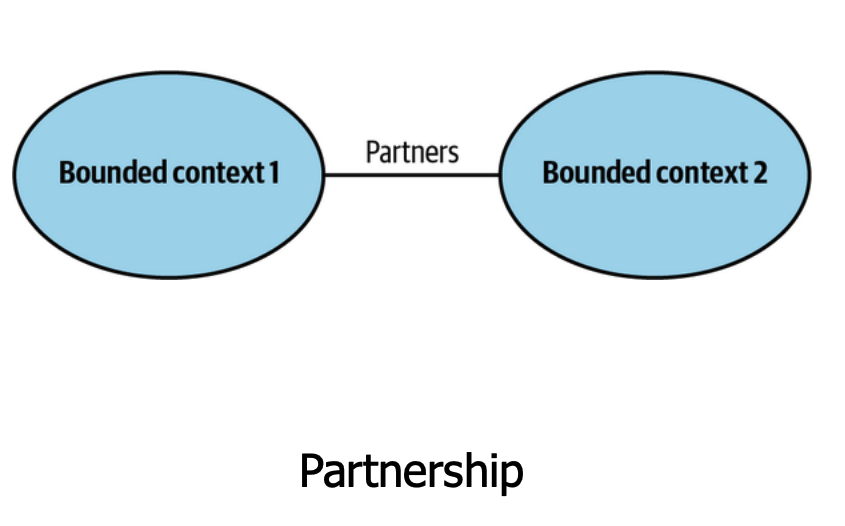
Partnership - Close alignment to share model/language:
-
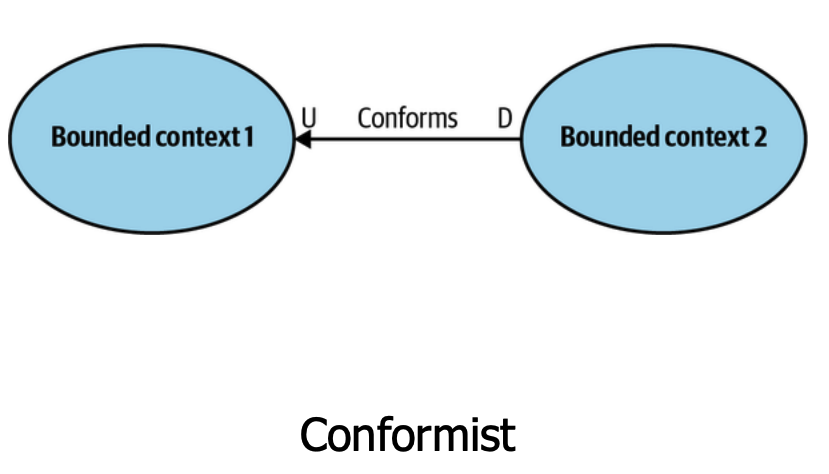
Conformist - One context follows the other's rules. Integrations with external SaaS APIs end up conformist as we must adapt to their interface, often offering an Open Host Service with a Published Language.
Here is my attempt at translating the continuation of the article to English:


Open Host Service
- It's a facade (an abstraction of a more complex system). A bounded context can make a set of services available using a standard protocol and comprehensive documentation for those interested in integrating.
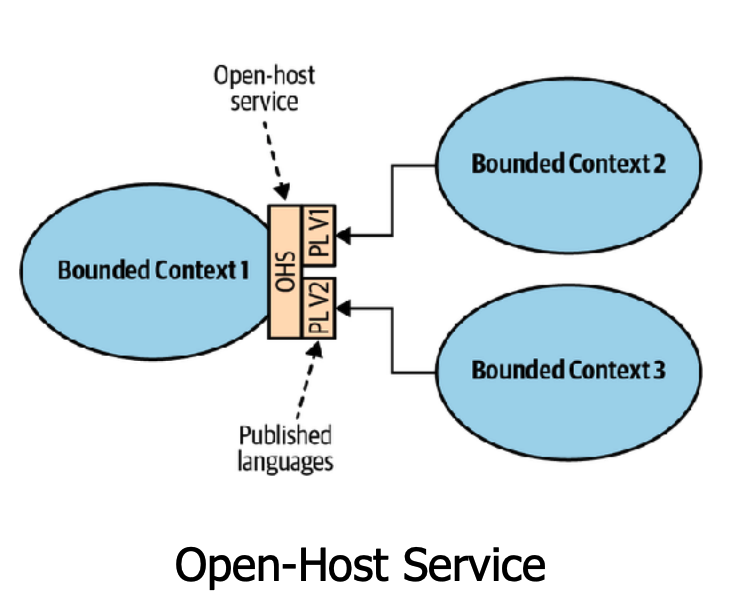
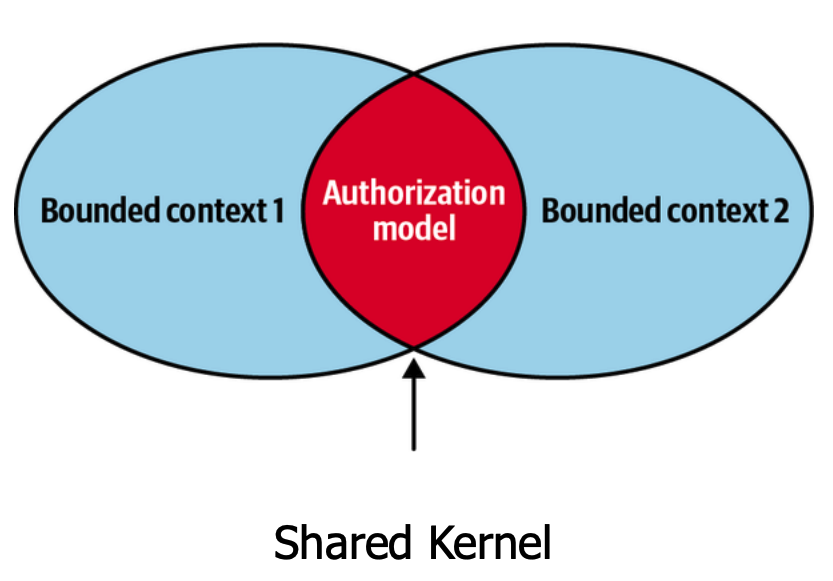
- Shared Kernel - Two or more teams can work in a synchronized way on a delivery that involves two or more bounded contexts. It's relatively common to share some common code between multiple bounded contexts, mainly for non-business related purposes like infrastructure.
Technically, the code can be shared through a direct relationship in a monorepo or some type of library that must be versioned and published internally so other bounded contexts can import it.
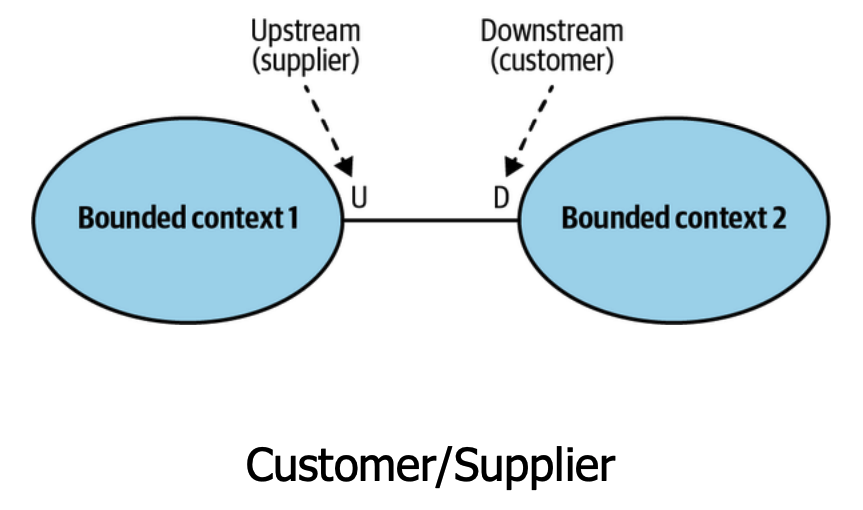
- Customer/Supplier - Contexts have divergent models but exchange data. There's a supply relationship where both the customer and supplier can determine what the contract between them should be.
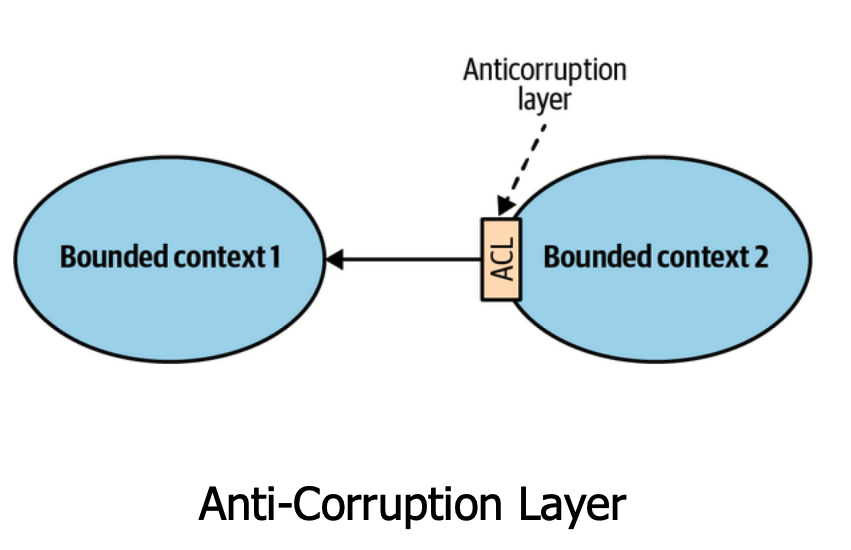
- Anti-Corruption Layer - Translates data/commands between contexts to avoid contaminating the domain with things from external bounded contexts.
Identifying and isolating the right bounded contexts allows teams to focus on modeling specific subdomains without over-engineering or overlap.
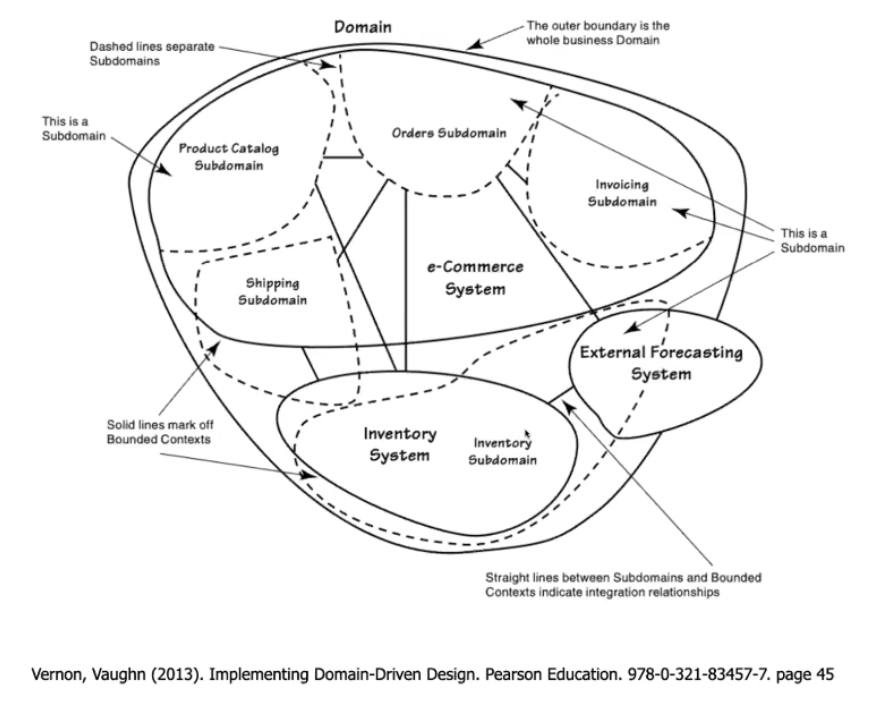
Not every bounded context needs to be developed the same way - one can use DDD and another Transaction Script.
The bounded context boundary is great for defining a microservice.
Microservices
- Scalability - More related to infrastructure. Queueing theory or constraints theory -> The scalability bottleneck moves around - machines (load balancer) -> database (Aurora, Elastic) -> 3rd party APIs (DDOS Block) -> With async communication this is solved.
- Service independence -> Microservices add more failure points compared to monoliths. If communication is sync, dependency will exist. However, if async that dependency decreases.
- Availability -> Microservices decrease availability
- Fault tolerance -> Circuit breaker to block transactions so there are no active processing during deployments.
- Resilience -> Ability to keep functioning and recover from failures
What are the advantages and disadvantages of having a microservices architecture?
Advantages
- Technology diversity
- Better technical debt control
- Easier to follow tech evolution (smaller codebase)
Challenges
- Distributed transactions
- Harder to handle and diagnose errors
- Higher technical complexity
With good strategic modeling:
- Complexity partitioning
- Smaller teams
- Reuse
A monolithic architecture isn't always bad. On the contrary! For smaller projects with small teams, especially early on when building a product, it's the architecture that yields the most results with least effort and infrastructure costs.

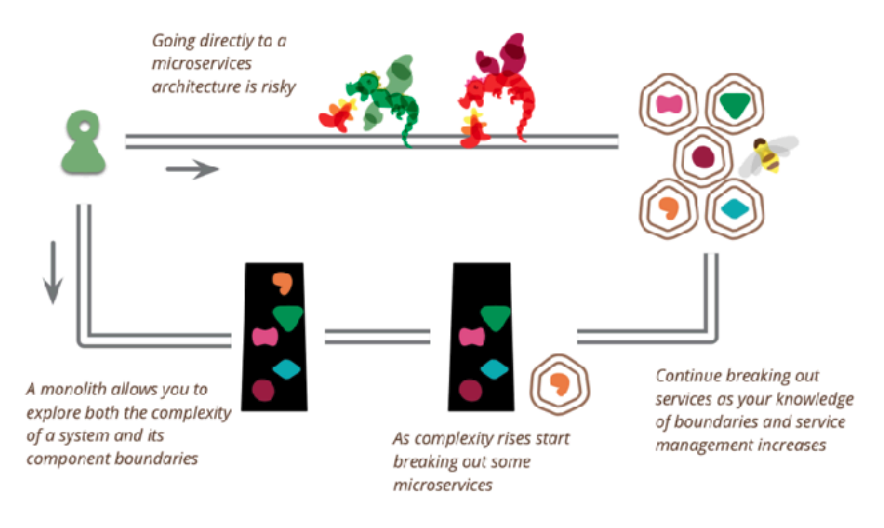
It takes time to understand the best way to divide bounded contexts.
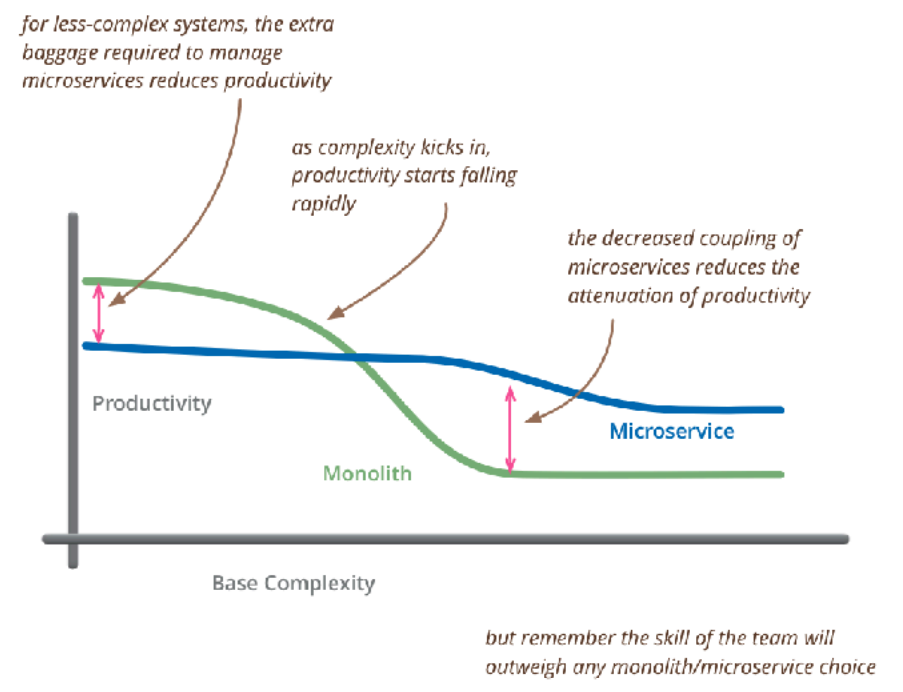
Consuming Distributed Data in a Microservices Environment
API Composition
The first way is using the API Composition pattern - invoking each service's interfaces to obtain the data, accumulating everything in memory.
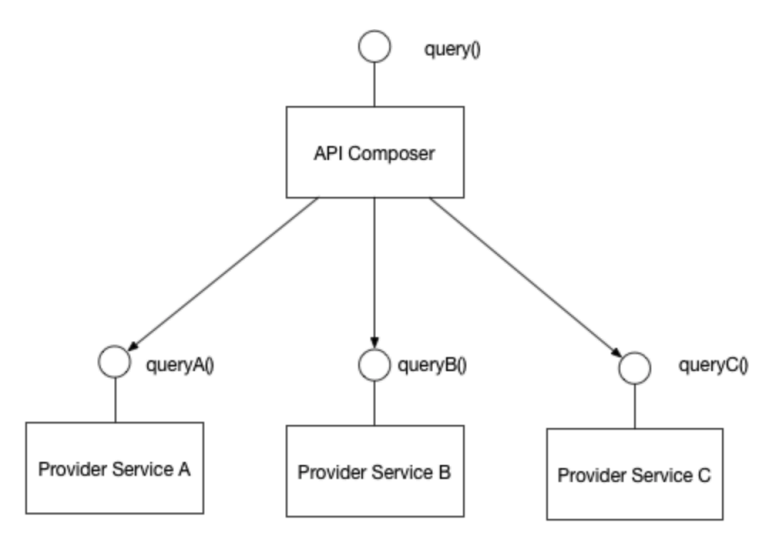
Due to the latency in obtaining each service's data, the response time can be long. There's also high memory consumption (data stays in memory longer).
Besides resource issues, available queries may not be adequate - e.g. how to return the top 10 highest grossing drivers in 2022? We'd need to request the payment service and then consult the driver by driverId in the account service, one by one.
CQRS
Another way is CQRS - Command Query Responsibility Segregation - popularized by Greg Young. It involves separating the mutation data model from the read data model. Instead of normalizing data on every consumption, we create a projection of the formatted data on each write so it can be consumed multiple times.
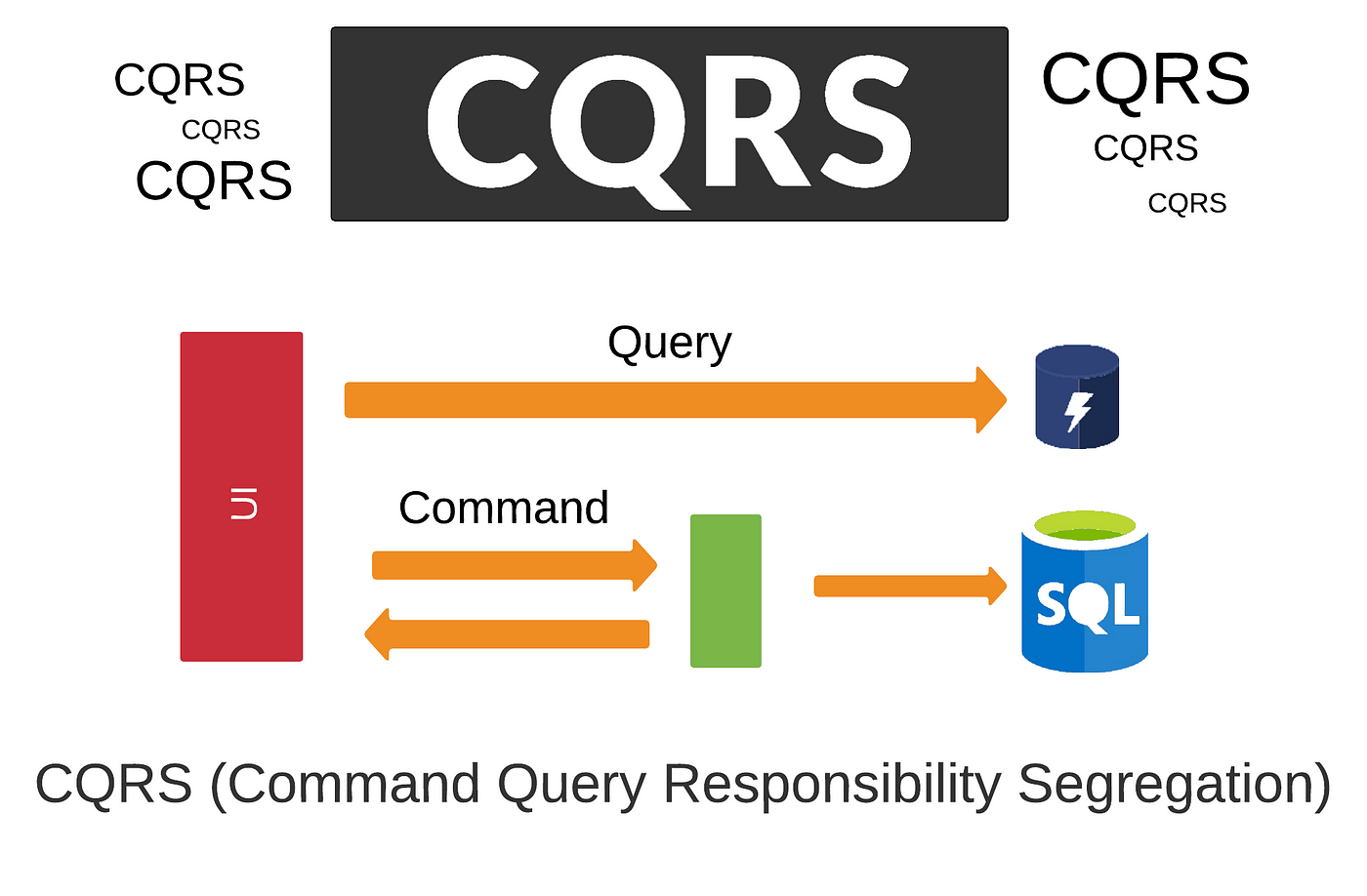
"Because the term command is widely used in other contexts I prefer to refer to them as modifiers, you also see the term mutators" - Martin Fowler
In other words, the mutation data model can and often should be different from the read data model - querying and reading are different things.
When using CQRS with DDD and repositories, each repository handles one aggregate. Since aggregates should be small, data from multiple aggregates may be needed to answer a query. This can get complex.
In a distributed scenario, data is also distributed. Obtaining related data from different sources adds complexity.
In general:
- Keep aggregates small
- Avoid repository overload
- Consolidate data from multiple sources at the query/read layer
- Separate complex queries from writes using CQRS
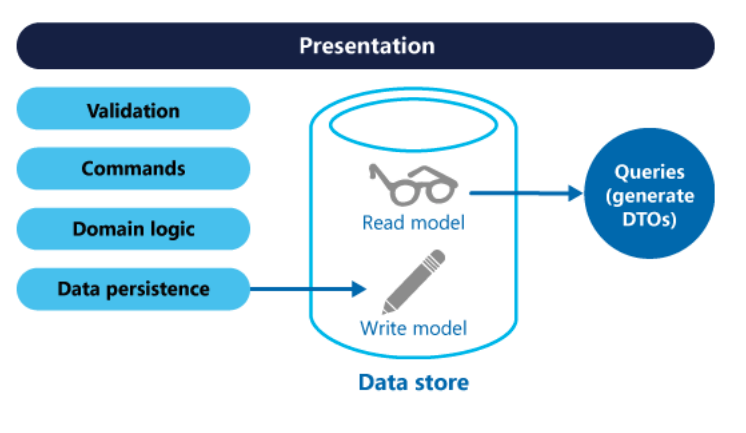
We can have the same database for reads and writes:
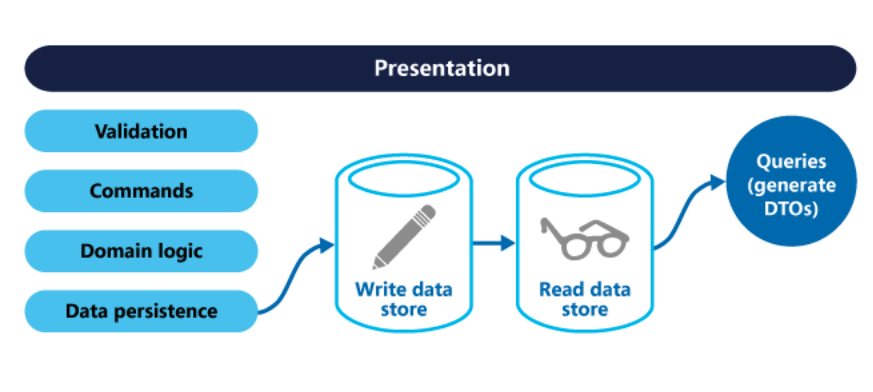
Or have a read-only replica:
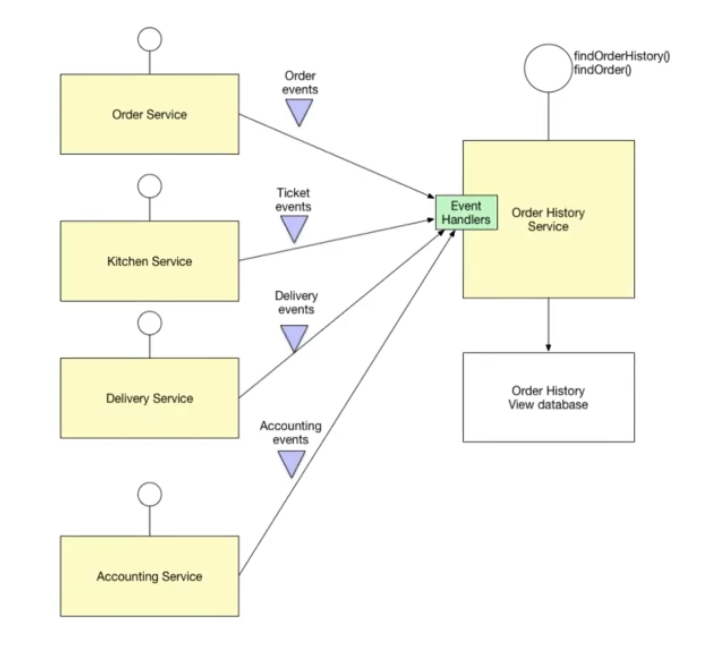
Another scenario involves microservices or distributed data environments. We can consolidate data in a separate base through events to serve queries.
Event Driven Architecture
Transaction
A transaction is an abstraction of a set of operations that should be treated as a single logical unit - to succeed, all operations must succeed or be undone.
ACID is a common transaction concept - Atomicity, Consistency, Isolation and Durability - related to commands executed in a relational database.
For example, a bank transfer transaction:
begin
insert into bank.transaction (id, type, amount) values (1, 'debit', 100);
insert into bank.transaction (id, type, amount) values (2, 'credit', 100);
commit
What if the first insert succeeds and the second fails? Rollback.
Unit of Work: We have multiple repositories and want to create a transactional context around them for rollback on errors. This context will keep the queries to run at the end of the transaction.
But what if not all transaction operations happen inside the database?
CAP Theorem
Can't have all three:
-
Consistency
-
Availability
-
Partition tolerance
-
CA: Without partitioning, data is consistent and available
-
AP: With partitioning, when opting for availability, consistency is lost if node connection fails
-
CP: With partitioning, when opting for consistency, availability is lost if node connection fails
There are many independent operations, which may or may not be distributed across different services.

The more complex and distributed the architecture, the more likely something goes wrong. Resilience is the ability to keep functioning and recover from failures.
Dealing With Transactions Resiliently
Retry, Fallback and even SAGA patterns can be adopted:
- Retry simply makes one or more retries in a short time interval - it can solve simple issues like packet loss, network fluctuations and even poorly-timed deployments;
- Fallback, when unavailable, tries another service - e.g. a large e-commerce site should work with multiple payment gateways to prevent downtime or even blocks;
- SAGA manages long-running distributed transactions through local transaction sequences. Not necessarily microservice-related - created in 1987, applies to any distributed long-running transaction.
Transaction Types
- Pivot: Go/no go transactions - flow execution continues or aborts based on them
- Compensable: Transactions to undo actions if overall transaction aborts
- Retriable: Execution guarantee that can recover from failures
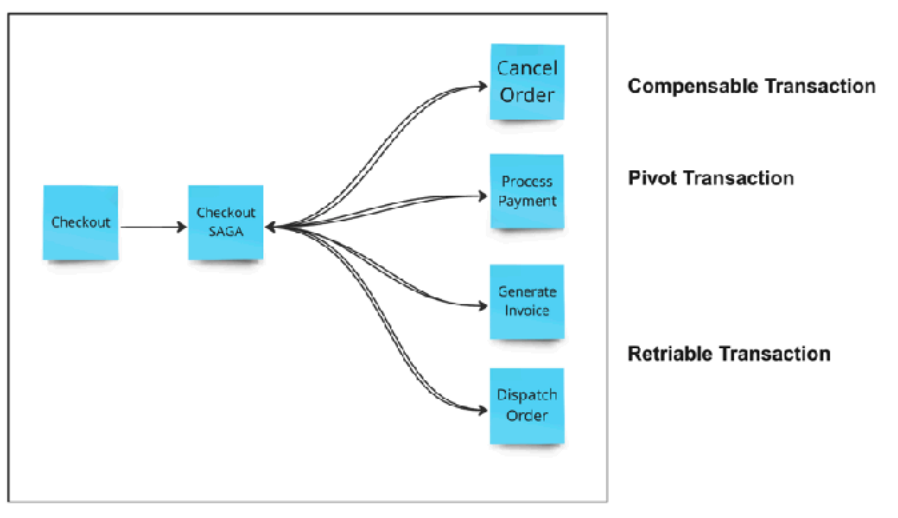
Saga Types
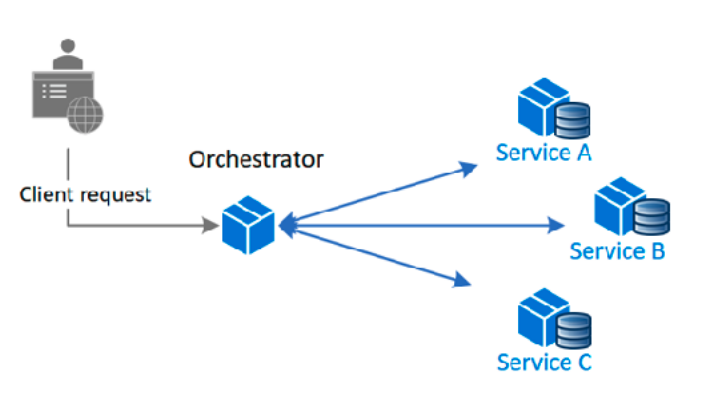
Orchestrated: Centralized orchestration logic coordinating each step (status machine).
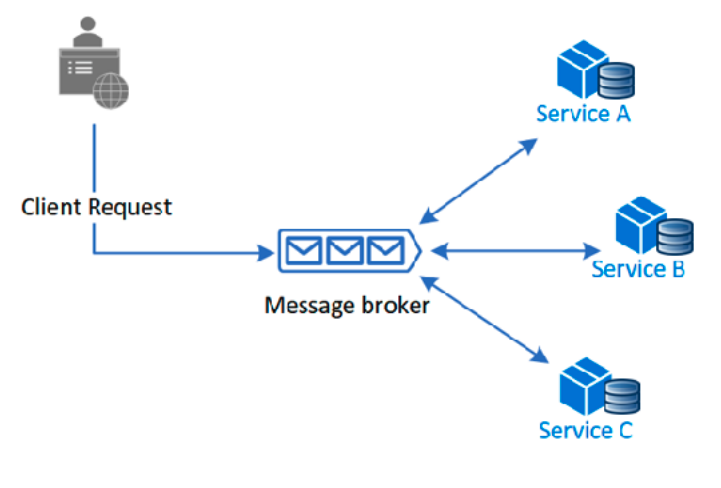
Choreography: Each participant publishes and handles events independently, deciding how to play its part.
Transactional Outbox
Message failure can be an architectural failure point, so we have a transactional outbox strategy - instead of attempting direct non-atomic action (event/message publishing), we use atomic operations (database writes) allowing subsequent execution of the desired action.
Event
Events are things that happened in the domain that can trigger business rules' execution.
Examples:
- OrderPlaced
- PaymentApproved
- InvoiceGenerated
- RideRequested
- RideEnded
- PositionUpdated
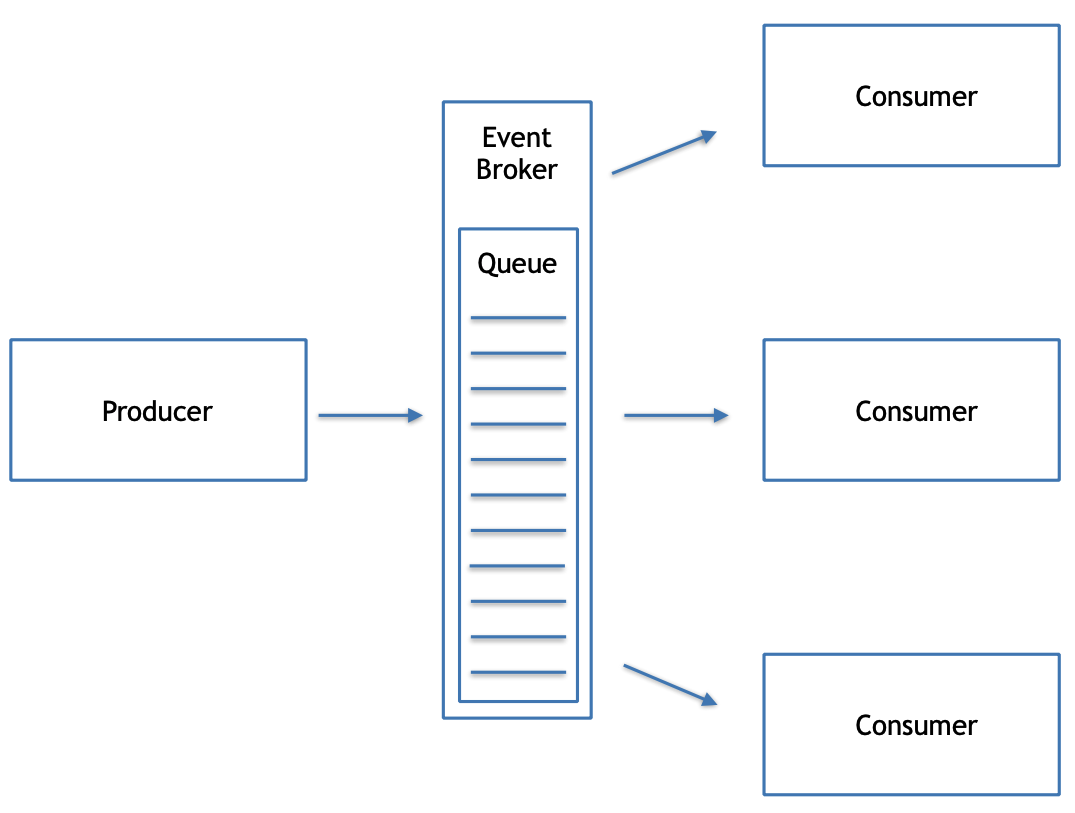
Why is the queue necessary?
Not enough available resources. Having resources to serve everyone immediately would be too expensive and wasteful during idle times.
Implementing queues
Locally via intermediary implementing an Observer/Mediator notification mechanism.
Over the network via messaging platform.
Some messaging platforms:
- RabbitMQ
- Kafka
- AWS SQS
- ActiveMQ
- Google Pub/Sub
- ZeroMQ
- Pulsar
Benefits of event-driven architecture:
- Loosely-coupled use cases inside and out services
- Failure tolerance - resumes processing where left off
- Better technical debt control
- Higher availability and scalability
- Lower infrastructure costs (add smaller machines)
- Better understanding of what happened, even Point-In-Time Recovery
Event-driven architecture challenges:
- Higher technical complexity
- Handling event duplication
- Unclear workflow
- Hard to handle and diagnose errors
Command
What's the difference between command and event?
While an event is a fact you need to decide how to handle, a command is a request - it can be rejected.
Commands are always imperative:
- PlaceOrder
- PayInvoice
- GenerateReport
- EnrollStudent
- UpdateCustomer
- UploadFile
- RequestRide
- UpdatePosition
The command handler pattern separates a synchronous request into two steps - receiving the command and processing the command. Typically applied in the controller upon receiving a request by firing a command.
Producer
import amqp from "amqplib";
async function main () {
const connection = await amqp.connect("amqp://localhost");
const channel = await connection.createChannel();
channel.assertQueue("test", { durable: true });
const input = {
rideId: "1234566789",
fare: 10
}
channel.sendToQueue("test", Buffer.from(JSON.stringify(input)));
}
main();
Consumer
import amqp from "amqplib";
async function main () {
const connection = await amqp.connect("amqp://localhost");
const channel = await connection.createChannel();
channel.assertQueue("test", { durable: true });
channel.consume("test", function (msg: any) {
console.log(msg.content.toString());
channel.ack(msg);
});
}
main();
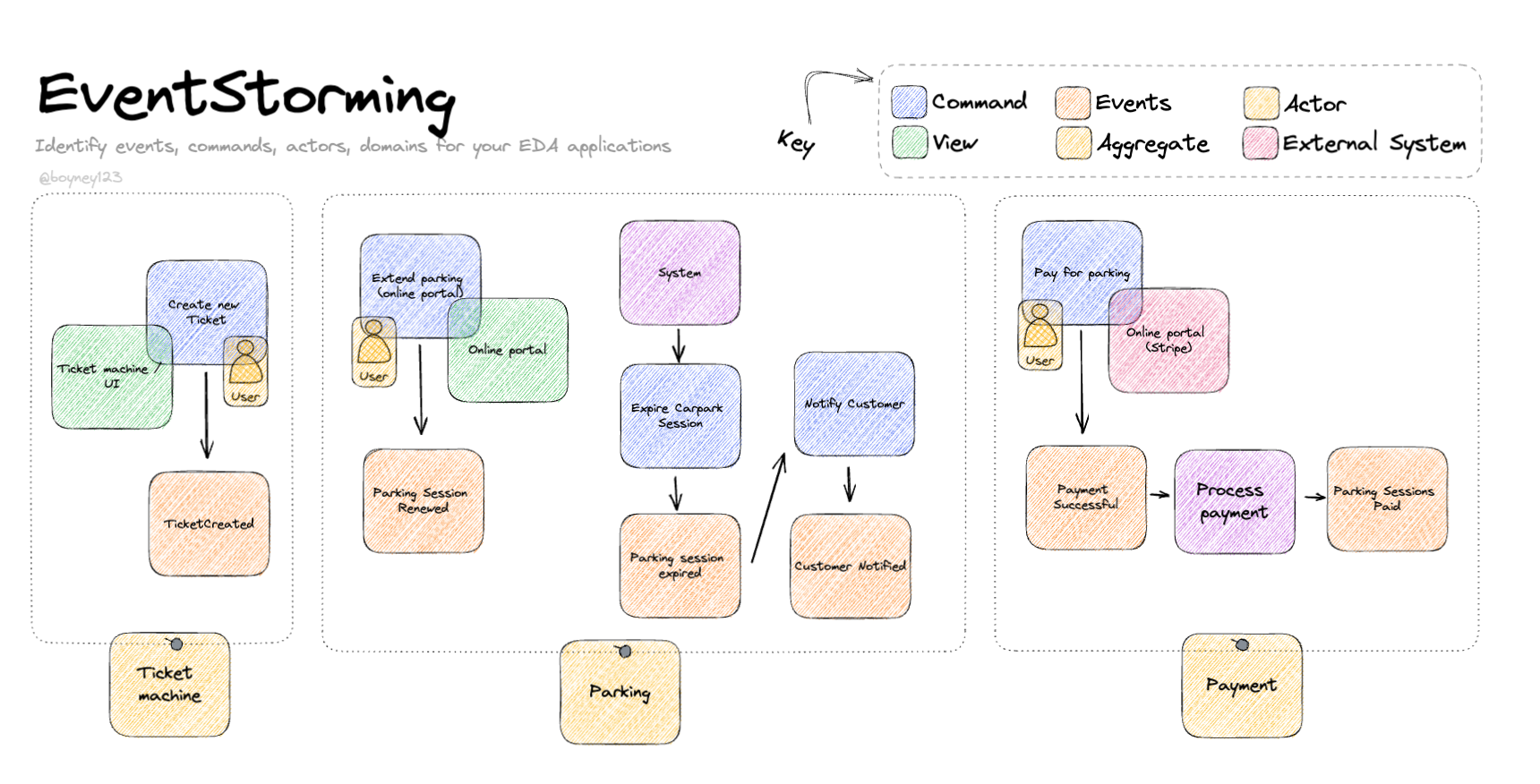
Event Storming
Event storming is a collaborative design technique to map complex business processes. The main event storming elements:
- Events: things that happened in the domain. Use past tense verbs (e.g. PaymentProcessed, CustomerRegistered).
- Commands: desired actions or events that haven't happened yet. Also use verbs (e.g. ProcessPayment, RegisterCustomer).
- Aggregates: a data cluster related to one entity or value object (Customer, Payment).
In an event storming session, team members gather and collaborate to map:
- Events occurring in the process
- Commands causing those events
- Aggregates involved in the events
The goal is aligning understanding of a complex domain and identifying unclear or problematic areas of the process.
The result is a visual map of event sequences and flows in the system. This helps extracting requirements and fostering valuable discussions among business, development and other stakeholders.