API - Application Programming Interface

HTTP
The Hypertext Transfer Protocol (HTTP) is a set of rules that allows machines with different configurations to communicate using a "common language." The HTTP protocol specification involves verbs, headers, and other concepts. HTTP is based on the client-server request-response model. When a client requests an internet resource, it sends a data packet containing headers to a URI. The recipient server then returns a response, which may be the requested resource or another header. In this way, HTTP enables communication between client and server machines on the internet.
URL - Uniform Resource Locator
Definition: Reference to the location (host) where a given resource is located on the internet.
Example: woliveiras.com.br
URN - Uniform Resource Name
Definition: Name that identifies a given resource, like a page or file.
Example: home.html, contact.php
URI - Uniform Resource Identifier
Definition: String of characters that uniquely identifies a resource on the internet.
Examples:
- https://woliveiras.com.br/front-end-developer/
- https://en.wikipedia.org/wiki/Hypertext_Transfer_Protocol
The URI combines the protocol (https://), the location (URL - woliveiras.com.br) and the resource name (URN - /front-end-developer/) to allow access to internet resources.

HTTP Response Status Codes
1. Informational responses (100–199)
2. Successful responses (200–299)
- 200 OK
The request has succeeded. The meaning of the success depends on the HTTP method:
- GET: The resource has been fetched and is transmitted in the message body.
- HEAD: The entity headers are in the message body.
- PUT or POST: The resource describing the result of the action is transmitted in the message body.
- TRACE: The message body contains the request message as received by the server.
3. Redirects (300–399)
4. Client errors (400–499)
- 401 Unauthorized
Although the HTTP standard specifies "unauthorized", semantically this response means "unauthenticated". That is, the client must authenticate itself to get the requested response. 5. Server errors (500–599) - 500 Internal Server Error The server has encountered a situation it doesn't know how to handle.
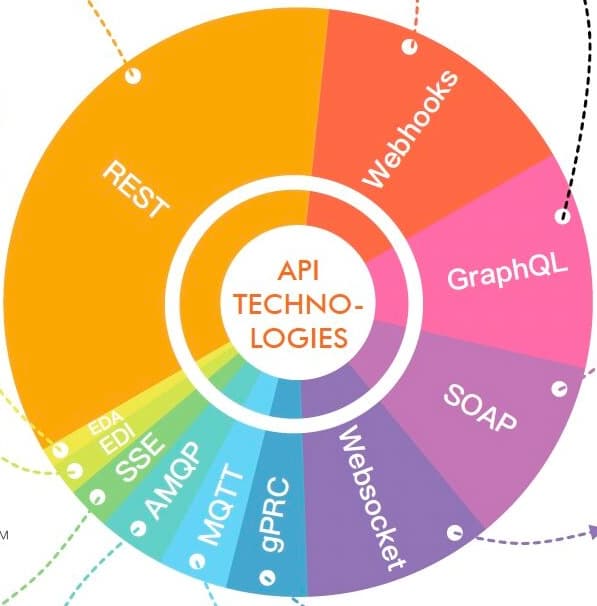
Protocols
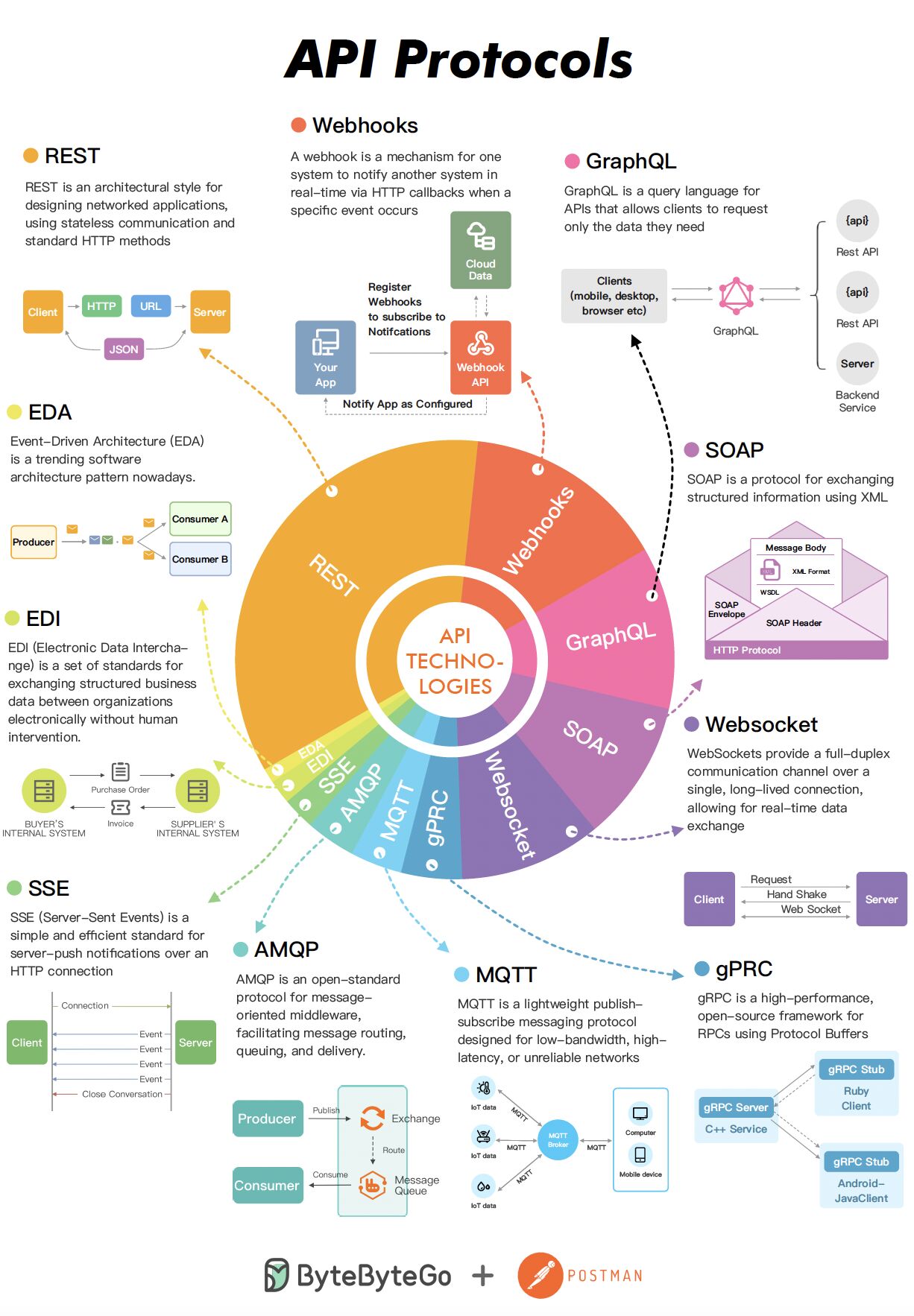
History
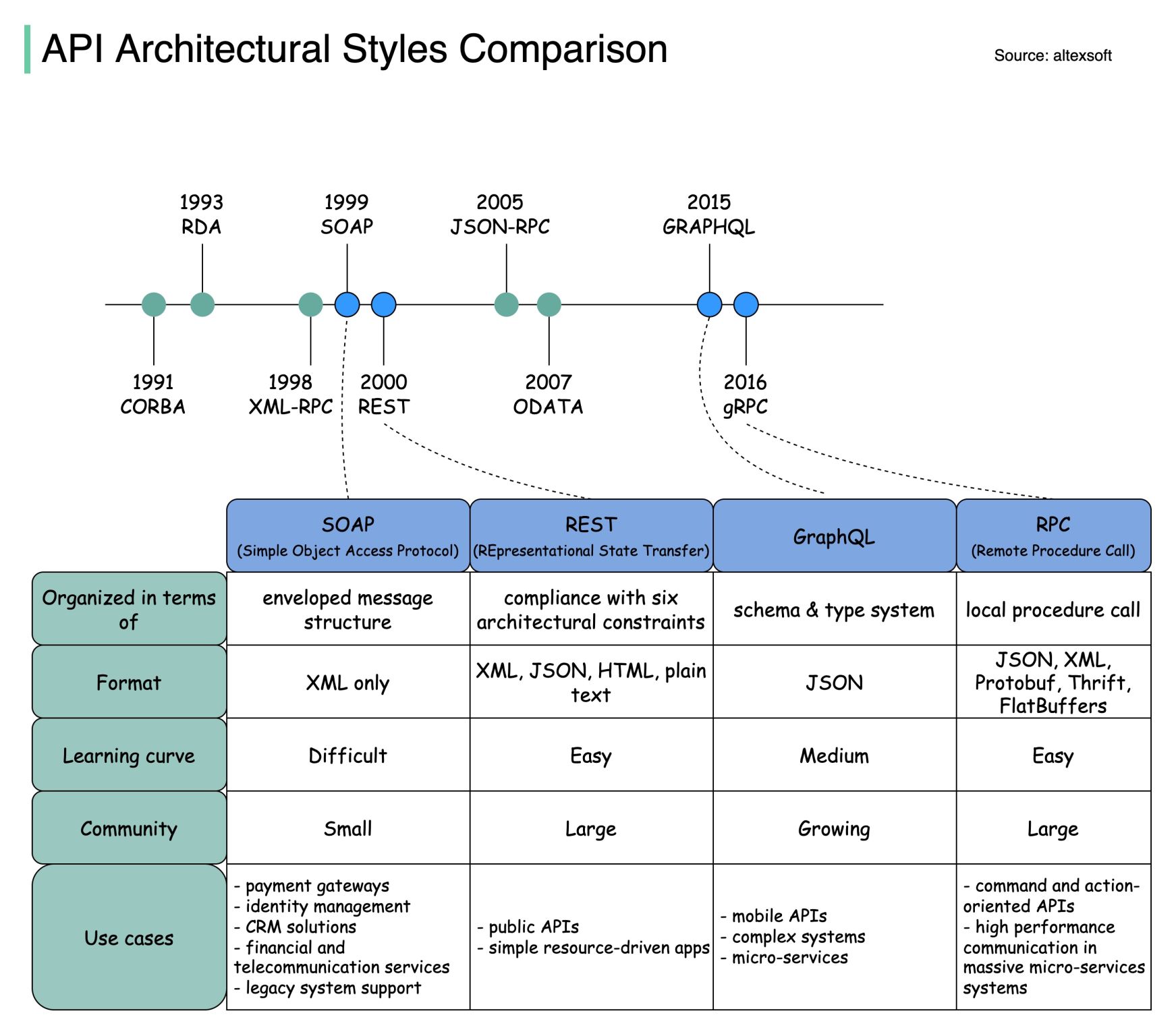
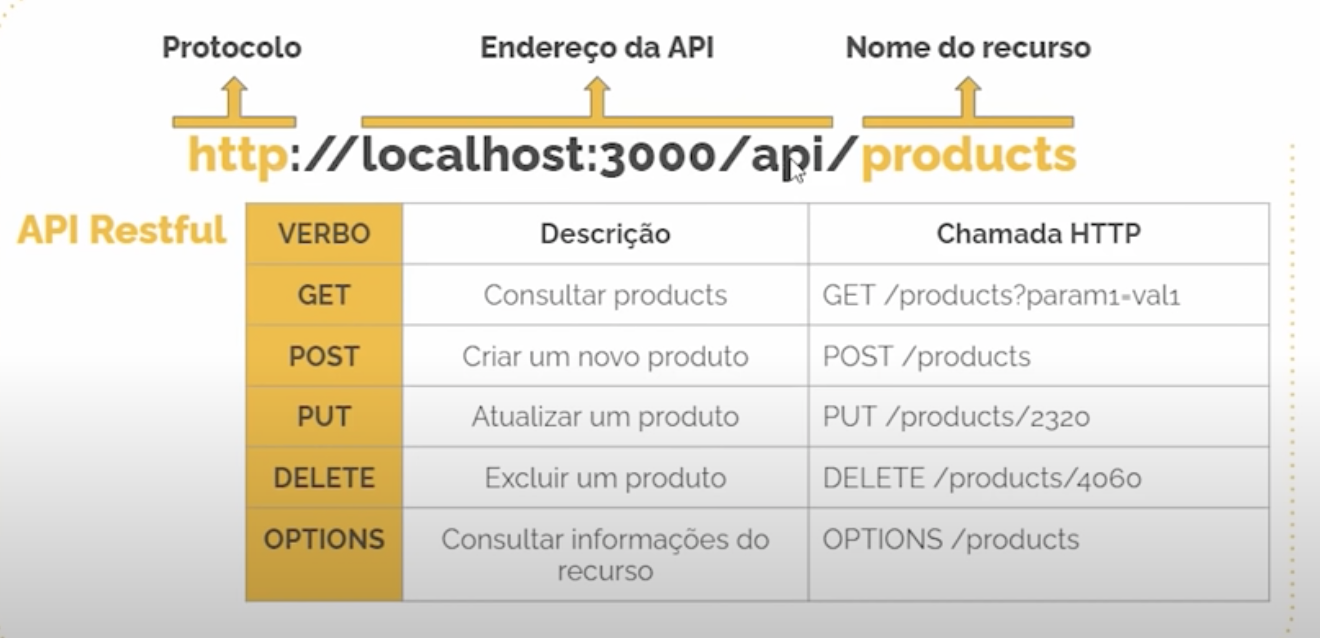
REST - Representational State Transfer
The standard architectural style for web APIs that uses HTTP methods for CRUD operations.
1 - Client-Server
2 - Stateless
3 - Cache
4 - Uniform Interface
• Resource Identification:
- http://serveraddress.com.br/products
- http://serveraddress.com.br/clients
• Resource Representation
• Self-descriptive Messages • HATEOAS (Hypertext As The Engine Of Application State) 5 - Layers
6 - Code On Demand
Know more: https://martinfowler.com/articles/richardsonMaturityModel.html
HATEOAS (Hypermedia as the Engine of Application State)
Is a design principle for RESTful APIs. It means that a REST API should provide links inside its responses to guide the client to other relevant endpoints.
Some of the main characteristics of HATEOAS include:
-
The API responses contain links (URLs) to available actions with each resource. For example, a response returning a user resource may include links to edit or delete that user.
-
The links provide a way to navigate the API without needing to know explicit endpoints upfront. The API is self-descriptive in this sense.
-
Reduces coupling between client and server, allowing the API to evolve independently. Clients can use dynamic links instead of hardcoded endpoints.
-
Links should be based on relationships between resources, like "next", "author", "search", to semantically give meaning to the available actions.
-
The use of HATEOAS allows different types of clients to use the same API. Less capable clients can simply follow links, while more advanced clients can access endpoints directly.
Implementing HATEOAS requires more design and development effort for APIs, but makes APIs more flexible, decoupled and long term durable. It is considered by many a recommended practice for REST APIs.
JSON:API
JSON:API is a specification for building APIs that follows similar principles to REST, but aims to provide more consistency and conventions around requests and responses.
Some key aspects of JSON:API include:
- Enforcing stricter rules around resource URLs, HTTP verbs, and response formats
- Standardizing the inclusion of nested related resources in responses
- Facilitating features like sorting, filtering, pagination through conventions
- Requiring use of the Content-Type: application/vnd.api+json header
While not as widely adopted as REST, JSON:API provides a more opinionated and standardized way to build APIs that can improve consistency across different client applications.
GraphQL
An alternative to REST that allows fetching API data with more flexibility and efficiency. Useful for Mobile and Web apps that need granular queries.
Cautions:
- With filters to avoid returning overly complex data that takes too long to resolve.
- With data security.
Webhooks
Event triggers that notify applications about data changes or updates. Useful for integrating third-party apps like Zapier and IFTTT.
EDA - Event Driven Architecture
A way to integrate enterprise applications with asynchronous, event-based communication, such as messaging queues (Kafka, RabbitMQ) and event streams.
EDI - Electronic Data Interchange
A standard for the electronic transfer of structured data between organizations, widely used in B2B commerce.
SSE - Server-Sent Events
A technique that allows a server to send updates to a client via HTTP asynchronously, without the client needing to keep polling.
AMQP - Advanced Message Queuing Protocol
An open protocol for asynchronous messaging with message queues.
MQTT - Message Queuing Telemetry Transport
A lightweight messaging protocol often used in IoT and machine-to-machine communication.
gRPC
A high-performance RPC framework that uses protocol buffers and HTTP/2. Learn more.
WebSockets
An advanced technology that provides real-time bidirectional channels over a TCP connection. Persistent connection between endpoints so that polling is not required. We perform a connection upgrade, upgrade type = websocket
SOAP
A standard protocol that uses XML for systems that integrate via data exchange.
WSDL - Web Services Description Language
XML-based language for describing SOAP Web services, exposed methods, and how to access them.
Features
Authentication and Authorization
Crucial mechanisms for protecting access to the API.
Authentication
Verifies the client's identity, usually through JWT or OAuth tokens.

Authorization
Determines what resources authenticated users can access.
Versioning
Allows multiple versions of an API to coexist, facilitating updates and migrations.
Documentation
Accessible description on how to use the API, usually with OpenAPI/Swagger.
Tools like Swagger UI automatically generate interactive documentation from OpenAPI specifications. Postman and Insomnia also have documentation features.
Request Throttling
Avoids server overload with request thresholds per client.
Proxies and API Gateways like Amazon API Gateway have configurable throttling policies. Clients that exceed the limits receive 429 Too Many Requests error responses.
This prevents a client from monopolizing the API and ensures fair use of resources for everyone. Client libraries like Axios also have intelligent retry/backoff mechanisms to deal with these limitations.
Pagination
Returns large data sets in small paginated chunks.
Pagination prevents the client from having to load hundreds or thousands of records at once, which could overwhelm it or the API.
Tools like the Cursor Pagination standard allow paginating results by returning a cursor to the next data set. Frameworks like Django REST Framework have built-in customizable pagination support.
On the client side, libraries like React Query for React, Apollo Client for GraphQL make handling paginated data easy, automatically fetching the next page when you scroll to the end of the data, for example.
Some common pagination patterns:
- Limit and Offset - Specifies maximum number of results and initial offset
- Cursor Pagination - Returns a cursor to the next data set
- Page Number + Page Size - Provides current page and page size
Proper pagination is essential for scaling APIs with large data volumes.
Caching
Improves performance by reducing overfetching with client-side and server-side caching.
- NextJS has native caching..
- Redis - A very fast, popular in-memory cache. Allows caching objects, lists, sets, etc.
- Memcached - Another widely used in-memory cache for simple data caching.
- Ehcache - Cache embedded in the JVM. Useful in Java applications like Spring Boot.
- Database Cache - Databases like PostgreSQL, MySQL and others have cache implementations within the database itself.
By caching frequently accessed data and query results in the backend, we can drastically improve application performance and scalability, reducing unnecessary access to the database and other services.
The cache must be properly invalidated when data changes to ensure consistency. Tools like Redis have events and mechanisms that facilitate this automatic cache invalidation.
Monitoring
Tracks metrics, errors, and logs to detect and troubleshoot issues.
Tools:
Tools
Mock
- Json server - Needs to run in a parallel process
https://github.com/typicode/json-server - Miragejs - Runs in parallel, has a database.
https://miragejs.com/ - MSW - Mock Service Worker - Mocks at request layer https://github.com/mswjs/msw
- Mock API - https://mockapi.io/
API Gateway
- Kong - https://konghq.com/kong/
- Krakend - https://www.krakend.io/
Governance
- Backstage - https://backstage.io/

