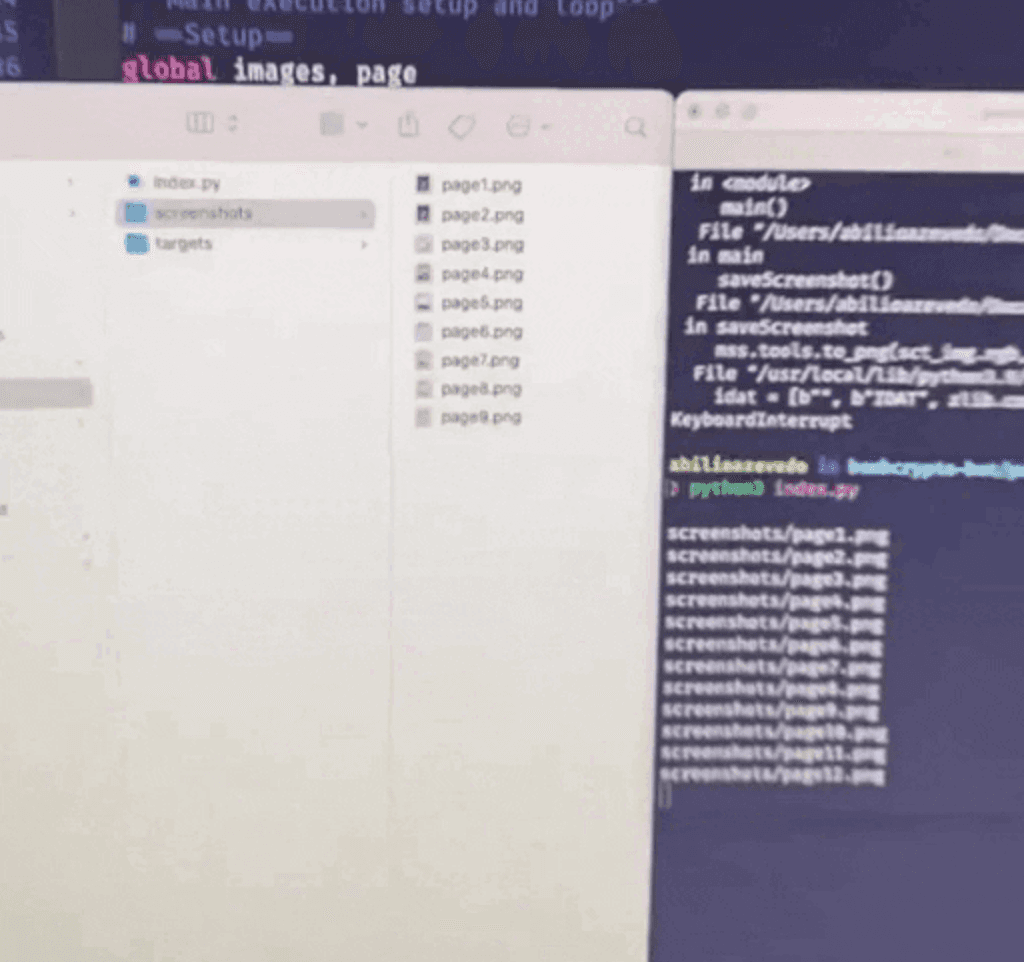
Screenshot Bot

Antes de mais nada quero deixar claro que não comercializei nem irei comercializar os materiais citados aqui neste artigo. Também deixar claro que paguei pelos acessos e conteúdos aqui citados. E que fiz os procedimentos aqui citados para estudo, prática de técnicas de engenharia reversa e de segurança de sistemas.
Recentemente voltei a estudar inglês em um curso para melhoria da pronúncia na escola Excellent Global que tem parceria com a Superlógica (empresa que trabalho atualmente).
Como é um curso remoto, eles liberaram acesso ao livro de forma virtual. O acesso é feito pelo site através de um login e senha. Porém, eu queria acessar o livro de maneira offline e poder escrever no livro digitalmente. Entretanto, não era possível porque o site em wordpress utiliza um plugin de segurança PDF Embedder Secure.
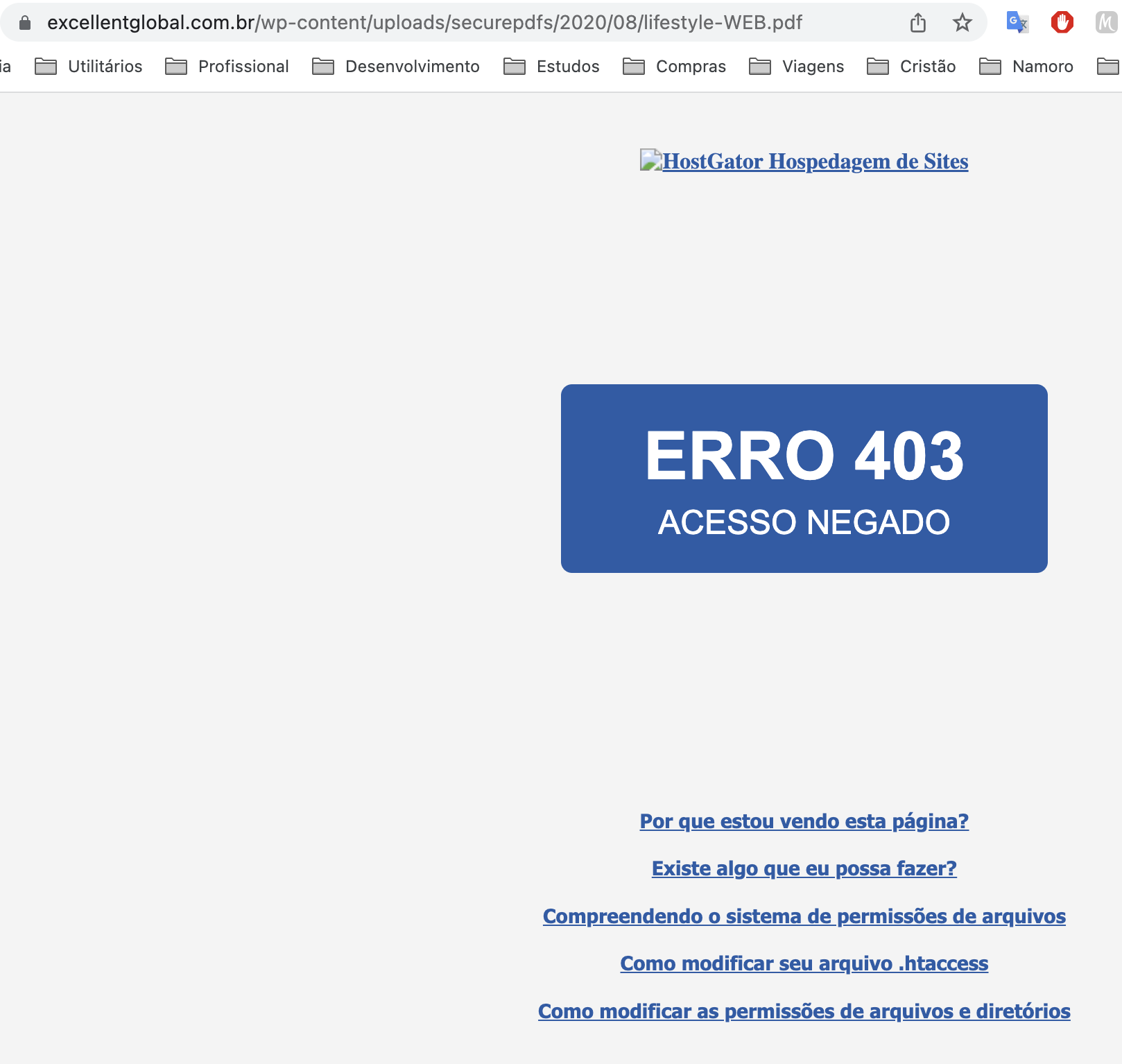
Os PDF originais ficam guardados em uma pasta de acesso protegido:
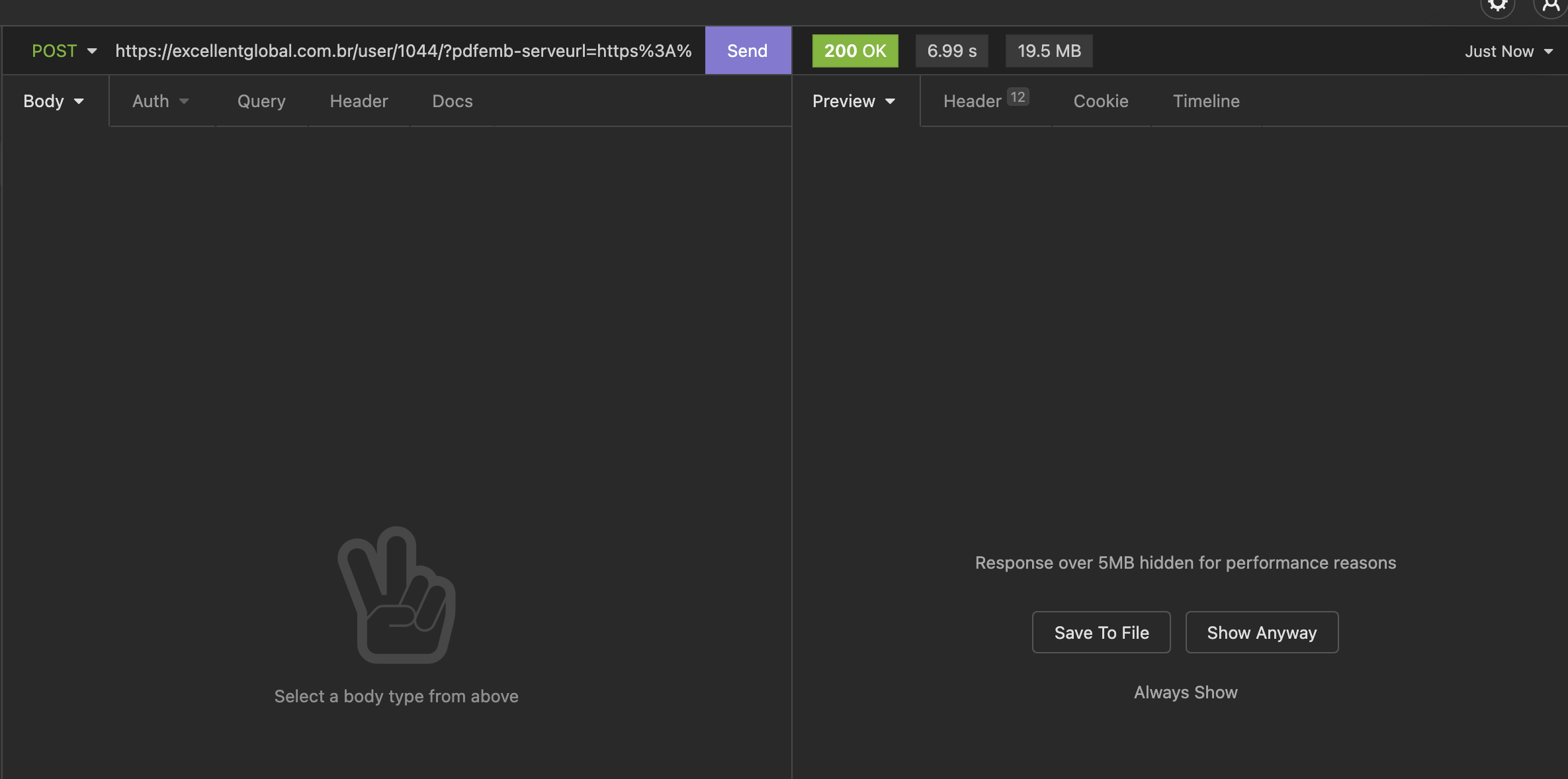
O plugin tem acesso a esta pasta e transforma o PDF em um arquivo binário encryptado no backend e baixa ele no frontend:
Com este binário o frontend, então, interpreta e converte para renderizar as páginas do pdf em tags canva no HTML:

Portanto, era preciso utilizar um algoritmo similar ao do plugin para interpretar e converter em PDF. Porém isso tomaria muito tempo, portanto decidi fazer um bot que tira fotos da tela e anda pra próxima página. Você encontra o código fonte do bot. Com isso consegui gerar o PDF do livro.
Para ir mais além no estudo de segurança do plugin, tentei acessar outros livros. Lembrando que eu paguei pelo acesso do livro mais avançado, pra mim os outros livros não tem importância, mas queria ver se era possível acessá-los. Para isso exportei o HTML recebido na página do livro e modifiquei a URL do livro que continha o nome "lifestyle" (ultimo livro) para "decision" (penultimo livro) e rodei esse HTML em um servidor local. Porém, cai no bloqueio de CORS e para by-passar esse bloqueio utilizei o plugin do Chrome Moesif Origin & CORS Changer com isso consegui rodar o script do plugin e acessar o livro Decision. Só consegui isso porque eles utilizaram um padrão de nome de arquivo muito fácil. O ideal é sempre utilizar identificadores randomicos para guardar seus arquivos no servidor.
Já reportei o problema para a empresa =)
Por fim, gostaria de indicar o vídeo que a Rocketseat fez junto com desenvolvedores do Grupo Primo falando sobre o desenvolvimento da plataforma de conteúdo deles. Nesse vídeo eles falam sobre Digital Rights Management (DRM) e as formas de proteger conteúdos digitais. Entre elas:
- Proteção em hardware para evitar o printscreen.
- Injetar códigos únicos por usuário no encode da imagem, vídeo ou áudio para identificar quem está compartilhando o conteúdo pirata. Por isso algumas TVs antigas não passam alguns conteúdos por não terem a proteção de DRM.

