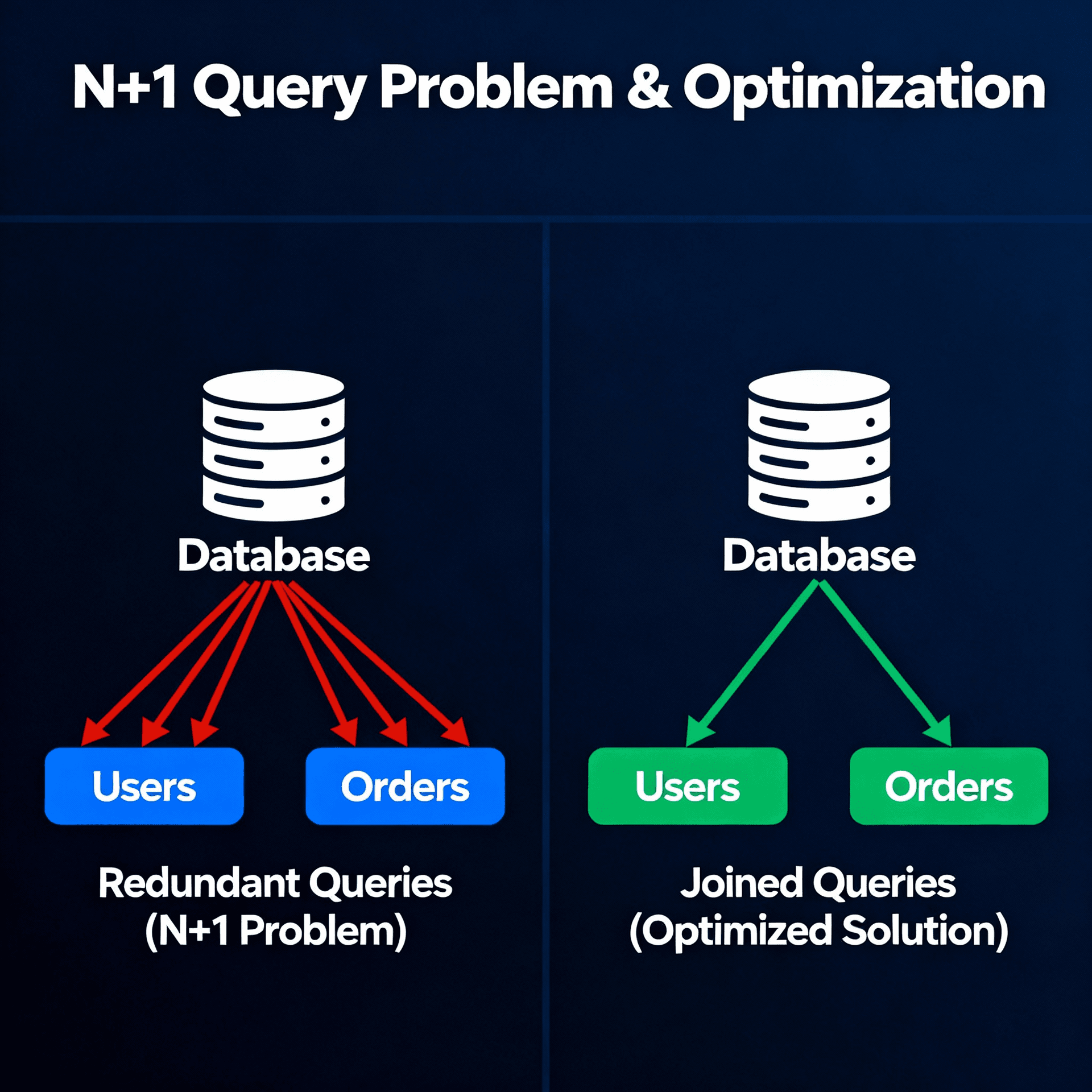
Data Engineer


In today's data-driven world, the role of a Data Engineer has become increasingly crucial. As organizations grapple with exponentially growing data volumes, the need for professionals who can design, build, and maintain data pipelines has never been more pressing. Let's dive deep into the world of Data Engineering and explore its key components, tools, and best practices.
Key Definitions and Concepts
Data Engineering
Data Engineering is the practice of designing and building systems for collecting, storing, and analyzing data at scale. It bridges the gap between raw data and data science, ensuring that data is:
- Clean and consistent
- Properly structured
- Easily accessible
- Efficiently processed
- Securely stored
Data Warehouse
A data warehouse is a centralized repository that stores structured data from multiple sources for reporting and analysis. Key characteristics include:
- Subject-oriented: Organized around major subjects like customers or sales
- Integrated: Consolidates data from various sources into a consistent format
- Time-variant: Maintains historical data
- Non-volatile: Data is stable and doesn't change once loaded
Types of Data Warehouses:
-
Enterprise Data Warehouse (EDW)
- Serves the entire organization
- Centralized architecture
- Strict governance and standards
-
Operational Data Store (ODS)
- Real-time or near-real-time data
- Current operational reporting
- Limited historical data
-
Data Mart
- Subset of a data warehouse
- Department or function-specific
- Focused on specific business areas
Data Lake
A data lake is a storage repository that holds vast amounts of raw data in its native format until needed. Characteristics include:
- Schema-on-read approach
- Supports all data types (structured, semi-structured, unstructured)
- Highly scalable and flexible
- Cost-effective storage
ETL vs. ELT
Both are processes for moving and transforming data, but with different approaches:
ETL (Extract, Transform, Load)
- Traditional approach
- Data is transformed before loading
- Better for sensitive data requiring cleaning
- Example flow:
# ETL Example
def etl_process():
# Extract
raw_data = extract_from_source()
# Transform
transformed_data = clean_and_transform(raw_data)
# Load
load_to_warehouse(transformed_data)
ELT (Extract, Load, Transform)
- Modern approach
- Data is loaded first, then transformed
- Better for big data and cloud environments
- Example flow:
# ELT Example
def elt_process():
# Extract and Load
load_raw_data_to_lake(extract_from_source())
# Transform in-place
execute_transformation_queries()
Data Pipeline
A data pipeline is a series of processes that move and transform data from source to destination. Components include:
- Data ingestion
- Data processing
- Data storage
- Data transformation
- Data serving
Example of a modern data pipeline:
from prefect import task, flow
from prefect import Task
@task
def extract_from_api():
"""Extract data from API source"""
return api_client.get_data()
@task
def transform_data(raw_data):
"""Apply business transformations"""
return process_raw_data(raw_data)
@task
def load_to_warehouse(transformed_data):
"""Load data to warehouse"""
warehouse_client.bulk_load(transformed_data)
@flow
def daily_data_pipeline():
raw_data = extract_from_api()
transformed_data = transform_data(raw_data)
load_to_warehouse(transformed_data)
Data Modeling Concepts
Star Schema
A dimensional modeling technique with:
- Fact tables (contain business metrics)
- Dimension tables (contain descriptive attributes)
Example:
-- Fact Table
CREATE TABLE fact_sales (
sale_id INT PRIMARY KEY,
date_key INT,
product_key INT,
customer_key INT,
quantity INT,
amount DECIMAL(10,2),
FOREIGN KEY (date_key) REFERENCES dim_date(date_key),
FOREIGN KEY (product_key) REFERENCES dim_product(product_key),
FOREIGN KEY (customer_key) REFERENCES dim_customer(customer_key)
);
-- Dimension Table
CREATE TABLE dim_product (
product_key INT PRIMARY KEY,
product_id VARCHAR(50),
product_name VARCHAR(100),
category VARCHAR(50),
brand VARCHAR(50)
);
Snowflake Schema
An extension of the star schema where dimension tables are normalized into multiple related tables.
Modern Data Stack Components
Data Integration Tools
Tools that connect to various data sources and load data into your warehouse:
- Fivetran: Managed connectors for 150+ sources
- Airbyte: Open-source ELT platform
- Stitch: Simple, self-service data ingestion
Data Transformation Tools
Tools that transform raw data into analytics-ready datasets:
- dbt (data build tool): SQL-first transformation
- Apache Spark: Large-scale data processing
- Apache Flink: Stream processing
Example dbt model:
-- dbt model for customer analytics
WITH customer_orders AS (
SELECT
customer_id,
COUNT(*) as order_count,
SUM(amount) as total_spent,
MIN(order_date) as first_order_date,
MAX(order_date) as last_order_date
FROM {{ ref('fact_orders') }}
GROUP BY customer_id
),
customer_profile AS (
SELECT
c.*,
co.order_count,
co.total_spent,
co.first_order_date,
co.last_order_date,
DATEDIFF(day, co.first_order_date, co.last_order_date) as customer_lifetime_days
FROM {{ ref('dim_customers') }} c
LEFT JOIN customer_orders co ON c.customer_id = co.customer_id
)
SELECT * FROM customer_profile
Data Quality and Testing
Data Quality Dimensions
- Accuracy: Data correctly represents reality
- Completeness: All required data is present
- Consistency: Data is consistent across systems
- Timeliness: Data is current and available when needed
- Validity: Data conforms to defined rules
Example data quality test:
def test_data_quality(df):
"""Basic data quality checks"""
tests = {
'null_check': df.isnull().sum().sum() == 0,
'duplicate_check': df.duplicated().sum() == 0,
'date_range_check': df['date'].between('2024-01-01', '2024-12-31').all(),
'value_range_check': df['amount'].between(0, 1000000).all()
}
return pd.Series(tests)
Modern Data Architecture Patterns
Data Mesh
A decentralized socio-technical approach where:
- Data is owned by domains
- Data is treated as a product
- Self-serve infrastructure is provided
- Federated governance is implemented
Lambda Architecture
A data processing architecture that handles:
- Batch processing for historical data
- Stream processing for real-time data
- Serving layer for query results
Example Lambda Architecture implementation:
# Stream Processing Layer
@app.stream(input='transactions', output='realtime_metrics')
def process_stream(transaction):
return calculate_metrics(transaction)
# Batch Processing Layer
def process_batch():
with spark.read.parquet('historical_data') as data:
return data.groupBy('date').agg(
sum('amount').alias('daily_total'),
count('transaction_id').alias('transaction_count')
)
Best Practices and Guidelines
Data Governance
- Document data lineage
- Implement access controls
- Define data retention policies
- Establish data quality standards
Performance Optimization
- Partition data appropriately
- Use appropriate indexing strategies
- Implement caching mechanisms
- Monitor query performance
Example optimization:
-- Partitioned table creation
CREATE TABLE sales_history (
sale_date DATE,
product_id INT,
amount DECIMAL(10,2)
)
PARTITION BY RANGE (sale_date);
-- Create partitions
CREATE TABLE sales_2024_q1 PARTITION OF sales_history
FOR VALUES FROM ('2024-01-01') TO ('2024-04-01');
Conclusion
Data Engineering is a complex field that requires deep understanding of various concepts, tools, and best practices. Success in this field comes from:
- Strong foundation in core concepts
- Practical experience with modern tools
- Understanding of business requirements
- Continuous learning and adaptation
As the field continues to evolve, staying updated with new technologies and patterns while maintaining a solid grasp of fundamentals will be key to success as a Data Engineer.