Arquitetura de Software


Arquitetura de Software
Arquitetura
- Define o paradigma de programação que será utilizado (orientação a objetos, funcional, etc.)
- Escolhe frameworks e bibliotecas que serão a base do sistema
- Determina padrões de comunicação entre componentes (API REST, RPC, filas de mensagens, etc.)
- Delimita tecnologias que podem ou não ser usadas
- Especifica a arquitetura de alto nível em camadas (apresentação, lógica de negócios, acesso a dados, etc.)
Design
- Define as responsabilidades e papéis de cada camada e componente
- Modela classes, interfaces e interações entre componentes
- Determina padrões de projeto a serem utilizados quando aplicável
- Especifica contratos e APIs de comunicação entre camadas/serviços
- Descreve fluxos de dados e operações essenciais do sistema
- Projeta o modelo de dados e esquema de banco de dados
- Lida com requisitos não-funcionais como desempenho, segurança e escalabilidade
Nós passamos a maior parte do tempo lendo código e não escrevendo código, por isso é importante um bom design.
Comportamento
É o que faz os stake holders ganharem ou economizarem dinheiro, é relativo ao domínio.
Estrutura
É o que mantém o comportamento de pé, sem collapsar, quanto mais comportamento for adicionado ao software, mais estrutura será necessária para suportá-lo de forma eficaz.
"Existem várias empresas que vão à falência com um software bem feito, mas poucas dão certo e tem sucesso ao longo do tempo com um software mal feito."
Refatoração
“Alteração feita na estrutura interna do software para torná-lo mais fácil de ser entendido e menos custoso de ser modificado, sem alterar o seu comportamento observável" - Martin Fowler
Ao refatorar considere sempre um código limpo.
Transaction Script
Organiza toda lógica principalmente como um procedimento único all this logic primarily as a single procedure
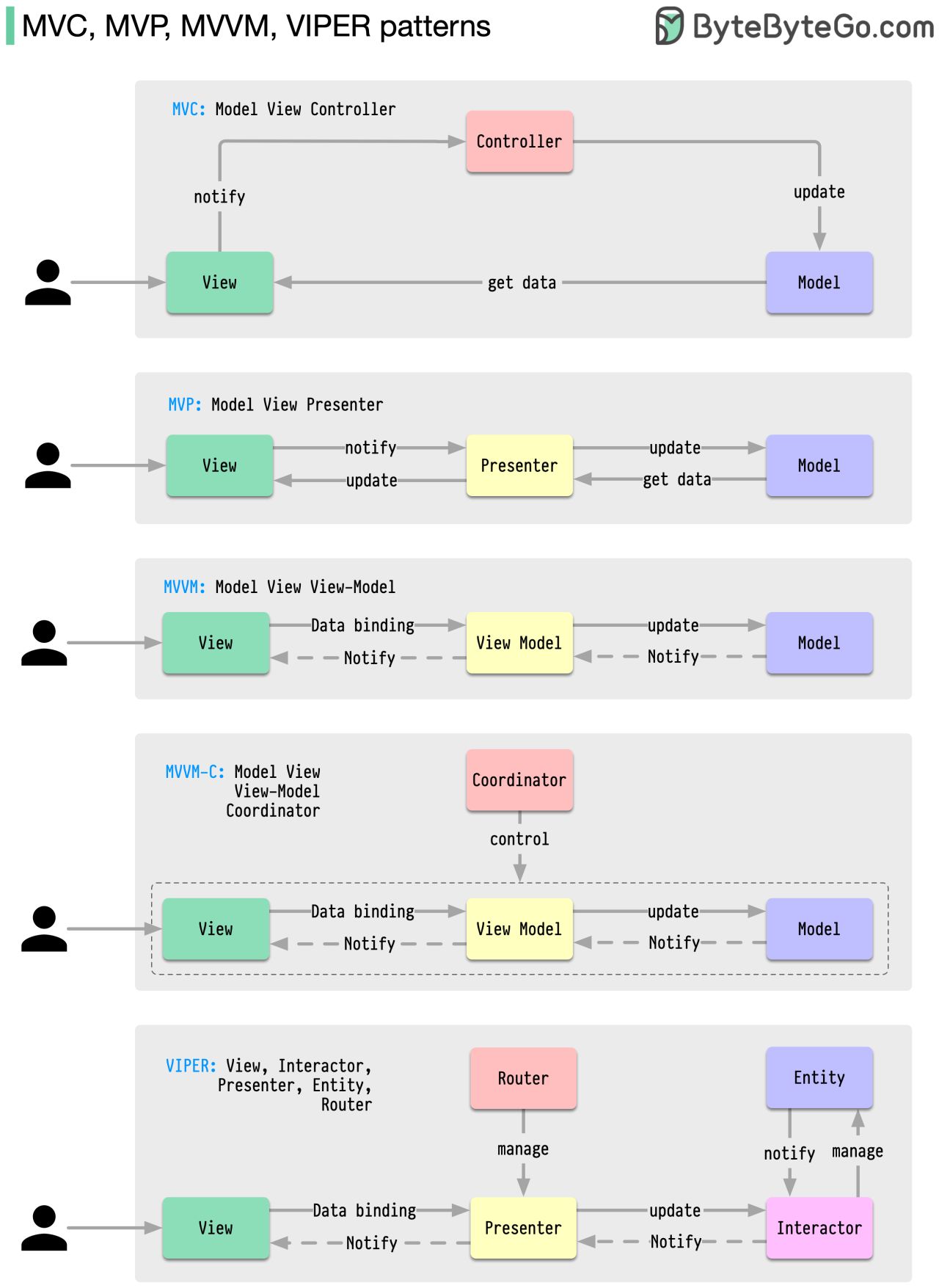
MVC, MVP, MVVM, MVVM-C, and VIPER
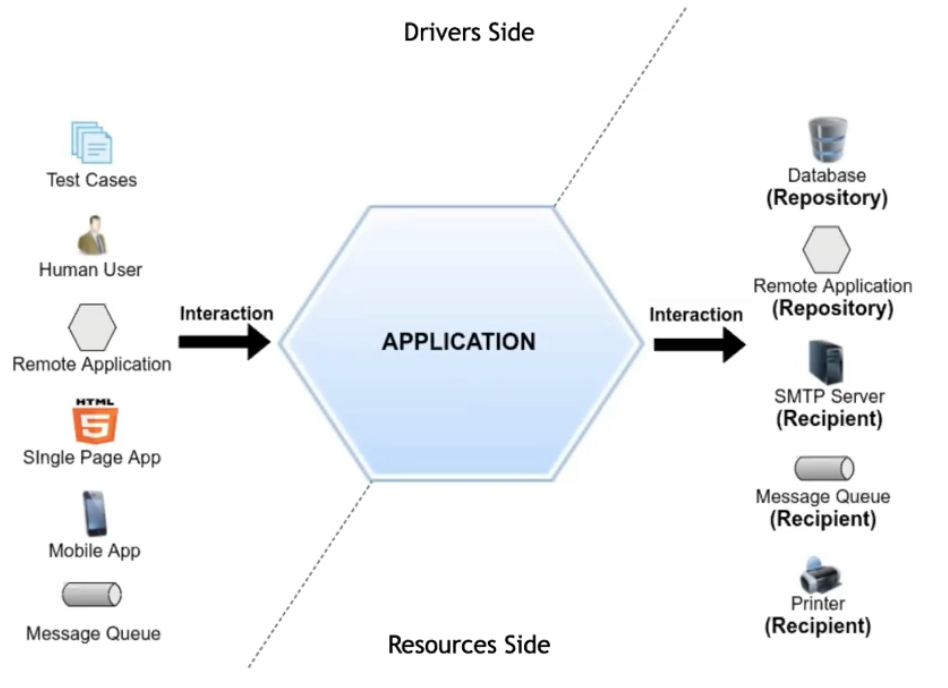
Arquitetura Hexagonal - Port and Adapters
"Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases" - Alistair Cockburn
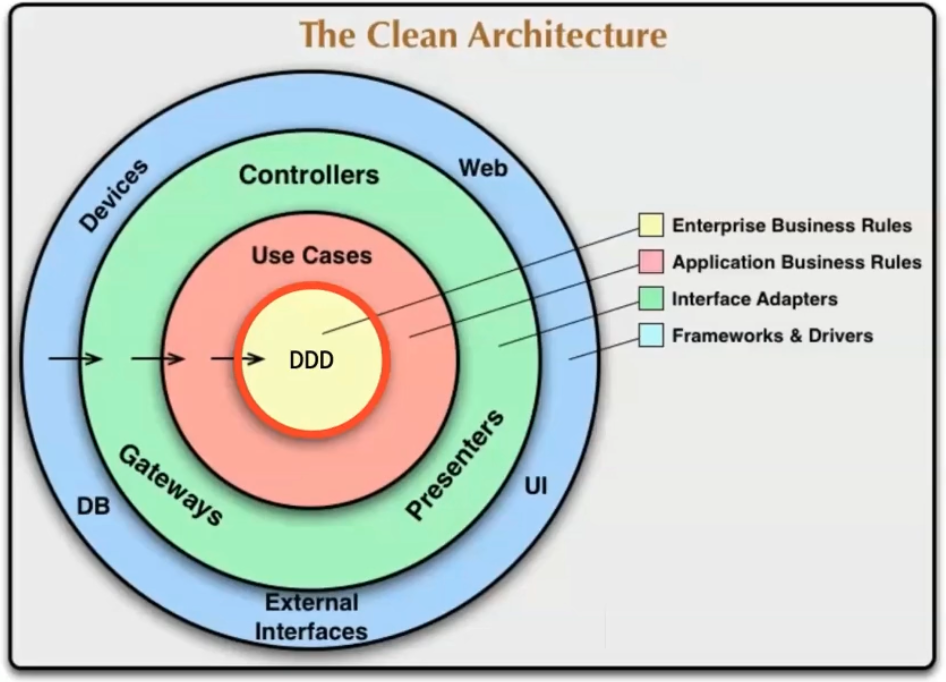
Quem está dentro não conhece quem está fora, mas quem está fora conhece quem está dentro, as entidades não conhecem os use cases e esses não conhecem a implementação dos interface adapters, que não conhecem a implementação dos frameworks and drivers.
Interface Adapters
- Fazem a ponte entre os casos de uso e os recursos externos
- Requisições HTTPS
- Acesso ao banco de dados (ORM ou SQL)
- Integração com API externa
- Leitura e escrita em disco
- Conversão de dados para formatos específicos.
Arquitetura Limpa
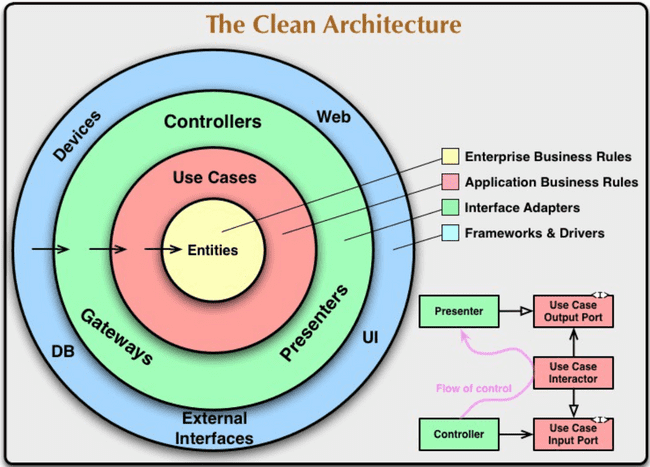
Use cases
"The center of your application is not the database, nor is it one or more of the frameworks you may be using. The center of your application is the use cases of your application" Robert Martin
- Realizam a orquestração das entidades e dos recursos externos
- Que fazem mutação, deve ser testado os efeitos gerados
- Que fazem leitura, deve ser testado o retorno
Princípios de Design Orientado a Objetos
- Encapsulamento - Esconder variações e complexidades internas
- Coesão - Manter relacionados o que é relacionado
- Acoplamento Baixo - Diminuir dependências entre módulos
- Separação de Interesses - Dividir por funcionalidades e especialidades
Benefícios da Arquitetura Limpa
- Código mais fácil de ler e entender
- Maior produtividade da equipe a longo prazo
- Reduz custos de manutenção e agrega valor ao negócio
- Permite evoluir o software junto com os requisitos
Arquitetura Limpa na Prática
- Começar pensando nos caso de uso e regras de negócio
- Aplicar padrões arquiteturais quando fizer sentido (MVC, por exemplo)
- Desenvolver orientado a testes (TDD)
- Refatoração constante conforme necessário
- Documentação vibrante e modelos visuais
Sinais de Problemas na Arquitetura
- Muitas dependências entre componentes
- Classes grandes e não coesas
- Testes frágeis e acoplados ao código
- Alto esforço para adicionar novas funcionalidades
Corrigindo Problemas de Arquitetura
- Quebrar grandes classes e módulos
- Aplicar princípios SOLID e padrões quando possível
- Introduzir camadas e separação clara por capacidades
- Evoluir a arquitetura junto com os requisitos
Conceitos
No livro PoEAA - Patterns of Enterprise Application Architecture temos a definição de:
- Table Module: junta regras de negócio e acesso à dados (separando os componentes por tabela)
- Table Data Gateway (DAO - Data Access Object): trate todo acesso à tabela em um mesmo lugar. Uma DAO vira repository quando conhece (recebe e devolve) entidades de domínio.
- DTO: Data Transfer Object - Os usecases não expõe objetos de domínio, eles expõe DTOs (contratos).
Camada Main
O main é o ponto de entrada da aplicação (HTTP, CLI, UI, Testes), é lá que as fábricas e estratégias são inicializadas e as injeções de dependência são realizadas durante a inicialização
"When composing an application from many loosely coupled classes, the composition should take place as close to the application's entry point as possible. The Main method is the entry point for most application types. The Composition Root composes the object graph, which subsequently performs the actual work of the application"
Containers de injeção de dependência (CID)
São úteis para gerenciar as dependências entre os objetos e classes em uma aplicação. Alguns motivos para utilizar CIDs:
- Facilita o desacoplamento de classes - Como as dependências são injetadas pelo container, as classes ficam fracamente acopladas. Isso permite modificá-las e testá-las mais facilmente.
- Evita a criação manual de dependências - O CID se encarrega de instanciar as classes e injetar as dependências necessárias. Isso simplifica o código cliente que utiliza essas classes.
- Permite reutilização e troca de implementações - Bastando configurar o CID, você pode instruí-lo a utilizar diferentes implementações de uma interface. Isso facilita reaproveitar e trocar códigos.
- Provê gerenciamento do ciclo de vida dos objetos - O container pode gerenciar quando objetos são criados e destruídos. Isso é importante em aplicações mais complexas para liberar recursos.
- Funciona bem com padrões como Injeção de Dependência e Inversão de Controle - Esses padrões podem ser mais facilmente implementados utilizando um CID.
Em resumo, o uso de containers de injeção de dependência facilita a escrita de códigos mais desacoplados, testáveis e que podem ser mantidos e extendidos com mais facilidade. Isso compensa a complexidade extra de configurá-lo e integrá-lo na aplicação.
Domain Driven Design
Complementa a camada de Entities do Clean Architecture, que não define as entities. É um design aplicado a camada de domínio.
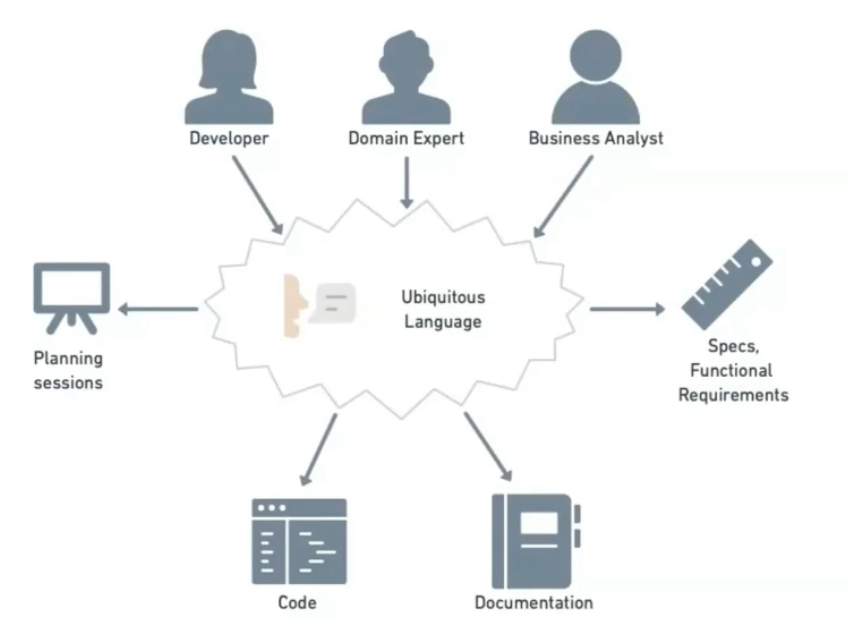
Domínio
É o problema, em termos de negócio, que precisa ser resolvido independente da tecnologia que será utilizada. Normalmente é difícil extrair o conhecimento relacionado ao domínio (Product Owner, Product Manager, Clientes...) A linguagem onipresente é a unificação do que é falado sobre o domínio.
Modelagem Tática
É utilizada para construir a camada de domínio e distribui a complexidade em objectos de domínio. Com o tempo, principalmente em um domínio complexo, vira uma bagunça. São muitas pessoas envolvidas, existe a integração de diversas áreas de negócio. Normalmente acontece um fenômeno conhecido como Big Ball of Mud.
Objetos de Domínio
Domain Objects vs ORM Objects
A forma de decompor/normalizar o domínio é diferente da forma de decompor/normalizar o banco de dados. No banco o ideal é não ter informações duplicadas, é preciso de uma otimização maior. Porém, se o sistema for simples, pode ser que aconteça.
Entidades (Entities)
Objetos que têm identidade própria e são distintos uns dos outros mesmo que possuam atributos iguais. Natureza é fazer mutação de dados (comportamento + dados). É um conjunto de dados junto com os comportamento.
Dominio Anêmico são os dados sem os comportamentos.
Como gerar a identidade?
- Manualmente: O próprio usuário pode gerar a identidade da entidade, por exemplo, utilizando o email ou um documento de identificação;
- Aplicação: A aplicação pode utilizar um algoritmo para gerar a identidade como um gerador de UUID;
- Banco de dados: O banco de dados por meio de uma sequência ou outro tipo de registro, centralizando a geração da identidade;
Exemplos: Usuário, Produto, Pedido.
Valores (Value Objects)
Objetos que se definem pelos valores de seus atributos e não possuem identidade própria, são imutáveis, ou seja, a mudança implica na sua substituição. Dois valores objetos com os mesmos atributos são considerados iguais. Também contém regras de negócio independentes. Serve para as Entities não ficarem muito grandes e pode ser reusado em várias entities.
Exemplos: Endereço, Data, Cor, Dimension, Password.
DICA: Uma técnica para identificar um value object é tentar substituí-lo por um tipo primitivo como uma string ou um número
Serviços de Domínio (Domain Services)
Encapsulam regra de negócio complexa relacionada a vários objetos de domínio, não tem estado. É indicado quando a operação que você quer executar não pertence a uma entity ou a um value object.
Exemplos: CalculadoraImpostos, GeradorBoleto.
DICA: Não crie serviços no lugar de entities e value objects, favorecendo um modelo anêmico
Fábricas (Factories)
Encapsulam a criação complexa de objetos de domínio, centralizando o conhecimento de como criá-los.
Agregados (Aggregates)
Um aggregate é um agrupamento, ou cluster, de objetos de domínio como entities e value objects, estabelecendo o relacionamentos entre eles. Grupo consistente de objetos de domínio que são tratados como uma única unidade. Garantem a consistência transacional.
DICAS:
- Um aggregate pode referenciar outros aggregates? Pode, mas por identidade
- Um aggregate pode ter apenas uma entidade? Pode e quanto menor melhor
- Uma entidade que faz parte de um aggregate pode fazer parte de outro? Não faz muito sentido, uma mudança na entidade utilizada por um aggregate poderia causar a quebra em outro;
#### Repositórios (Repositories)
Abstraem e encapsulam a camada de persistência, provendo uma interface simples para salvar e recuperar objetos de domínio. Tem como objetivo servir o domínio. Não deve ser usado para mostrar dados necessários pelo client. Ele traduz objectos relacionais externos (DB, API) para objectos de domínio. Para dados específicos do client usamos um CQRS.
Modelagem Estratégica
Modelagem Estratégica é como dividir meu domínio. Identifica e define as fronteiras entre os bounded contexts. Todo domínio pode e deve ser dividido em subdomínios.
Tipos de subdomínio
- Core ou Basic: É o mais importante e que traz mais valor para a empresa, é onde você coloca seus maiores e melhores esforços
- Support ou Auxiliary: Complementa o core domain, sem ele não é possível ter sucesso no negócio
- Generic: É um subdomínio que pode ser delegado para outra empresa ou mesmo ser um produto de mercado
Bounded Context
Um bounded context representa um limite conceitual em torno de um domínio ou subdomínio. Dentro desse limite, um modelo de domínio é válido e aplicável. Fora desse limite, o modelo não se aplica. Imagine um bounded context como uma forma de modularização de negócio que tem como objetivo reduzir o acoplamento interno do código-fonte (Big Ball of Mud).
Cada bounded context têm seus próprios:
- Modelo de domínio (entidades, valores, regras de negócio, etc)
- Linguagem Ubíqua
- Implementações específicas
Relacionamentos
Os bounded contexts interagem através de relacionamentos cuidadosamente gerenciados. Alguns tipos de relacionamento:
-
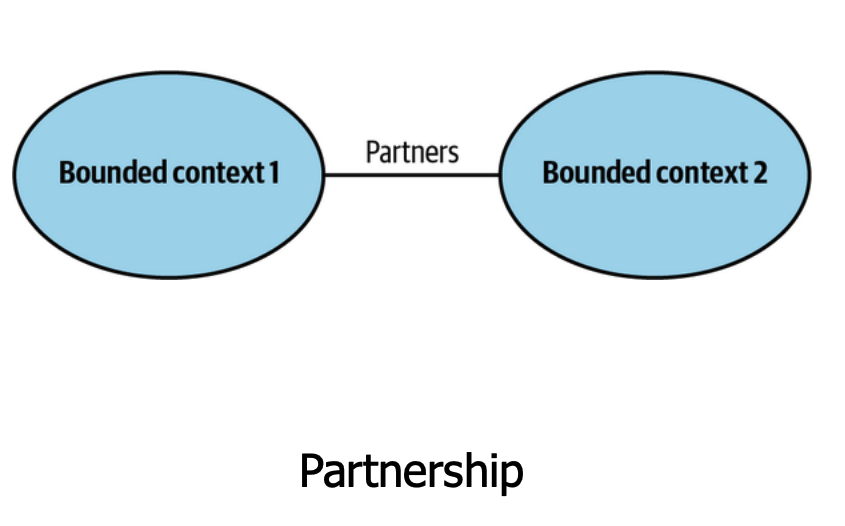
Parceria - Alinhamento próximo para compartilhar modelo/linguagem:
-
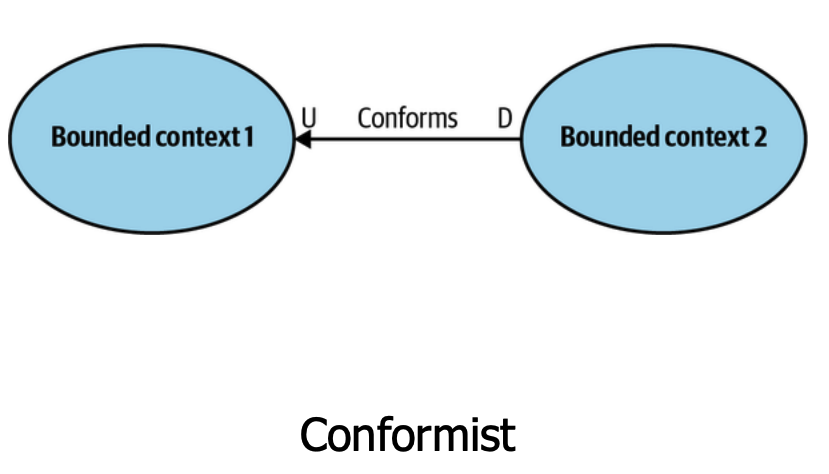
Conformista - Um contexto segue as regras do outro. Uma integração com uma API externa, contratada no modelo SaaS, acaba quase sempre sendo do tipo conformista já que temos que nos adequar a sua interface, nesses casos é normal oferecer um Open Host Service com uma Published Language.
-
Open-Host - é uma faixada (abstração de um sistema mais complexo). Um bounded context pode disponibilizar um conjunto de serviços utilizando um protocolo padrão e com uma documentação abrangente para quem tiver interesse em integrar.


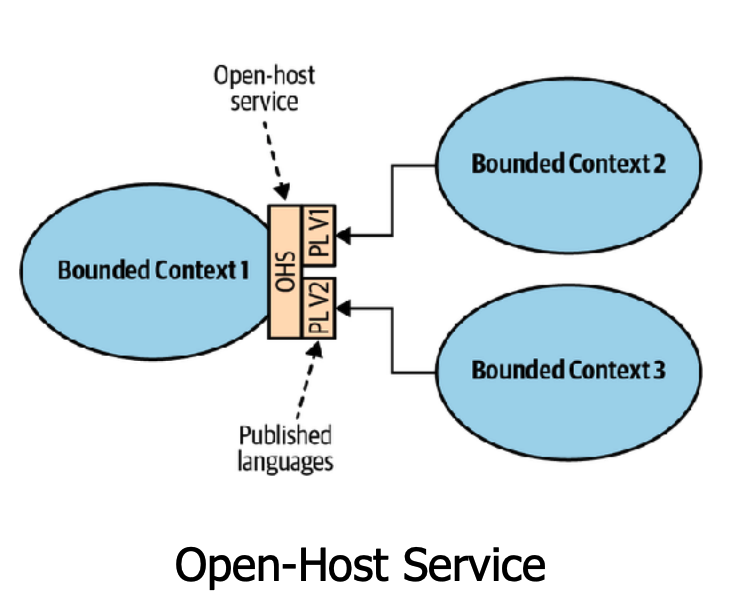
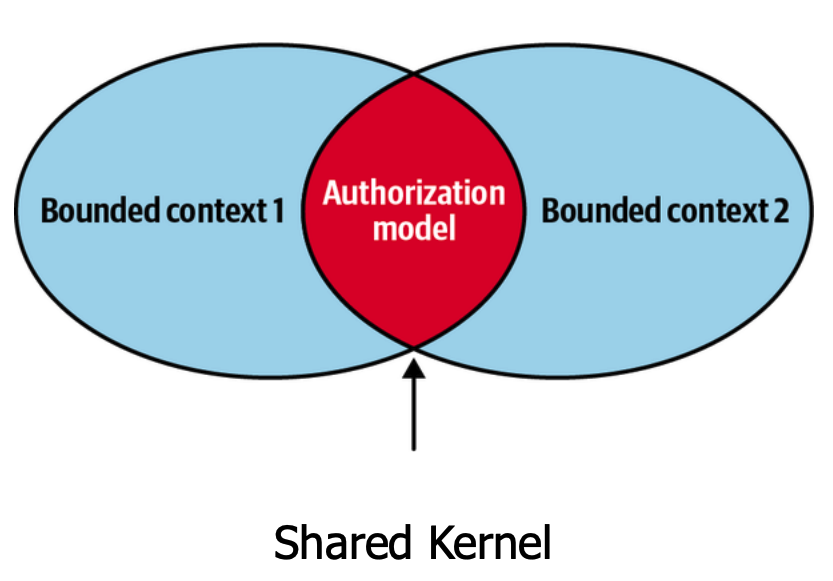
- Shared Kernel - Duas ou mais equipes podem trabalhar de forma sincronizada numa entrega que envolve dois ou mais bounded contexts. É relativamente normal compartilhar parte do código comum entre vários bounded contexts, principalmente por propósitos não relacionados diretamente ao negócio mas por infraestrutura
Em termos mais técnicos, o código pode ser compartilhado por meio do relacionamento direto em um monorepo ou algum tipo de biblioteca que deve ser versionada e publicada internamente para que possa ser importada pelos outros bounded contexts.
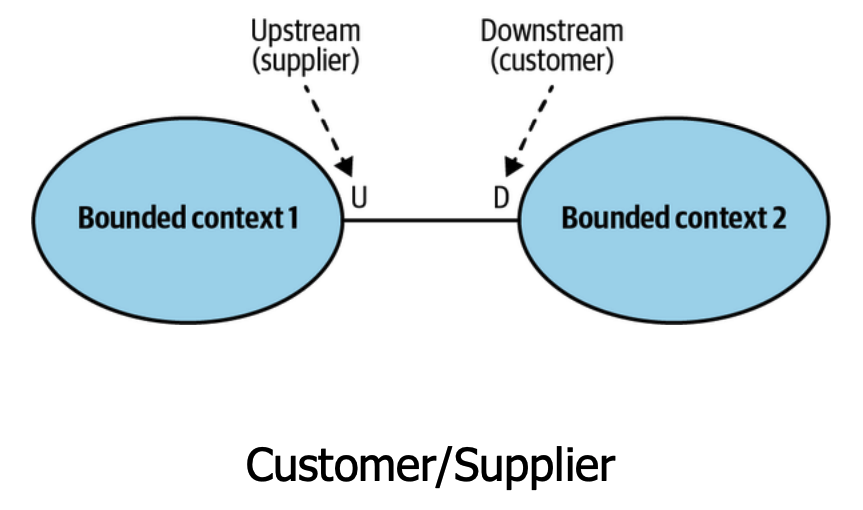
- Tolerância - Os contextos têm modelos divergentes, mas trocam dados. Existe uma relação de fornecimento onde tanto o customer quanto o supplier podem determinar como deve ser o contrato entre eles
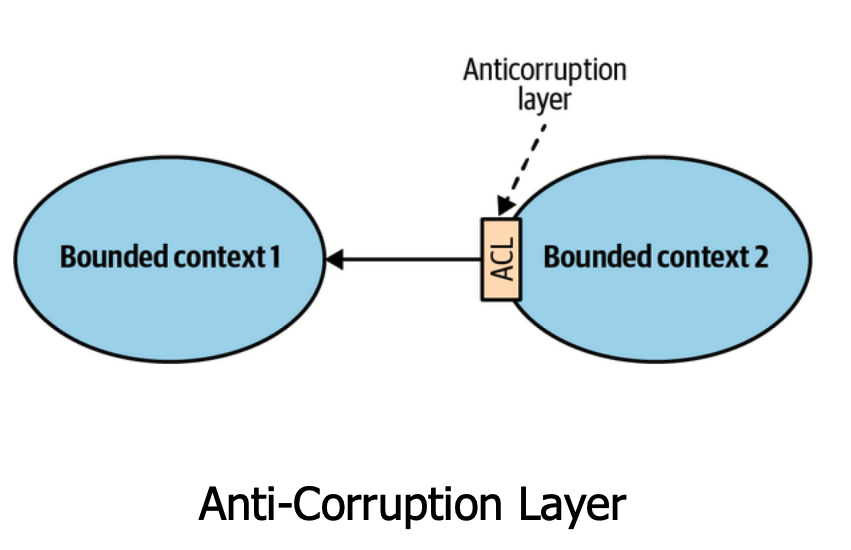
- Anti-corrupção - Traduz dados/comandos entre contextos para não contaminar o domínio com coisas de bounded context externos.



Identificar e isolar bounded contexts certos permite que equipes foquem na modelagem de subdomínios específicos sem over engineering ou sobreposição.
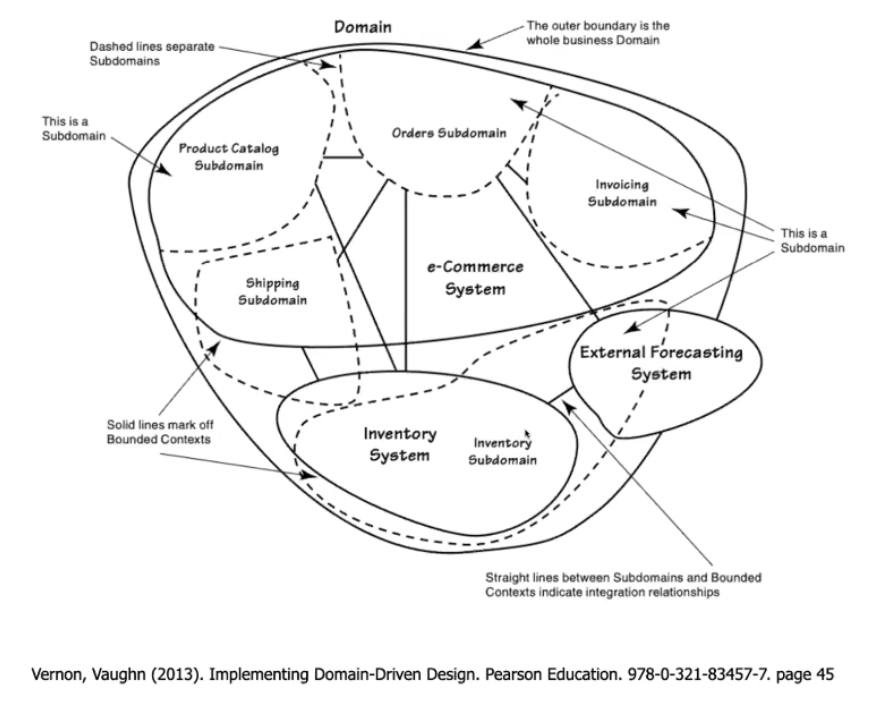
Nem todo bounded context precisa ser desenvolvido da mesma forma, um pode usar DDD outro TransactionScript A fronteira do bounded context é excelente para definir um microservice.
Micro-serviços
- Escalabilidade - Mais relacionado a infra estrutura. Teoria das filas ou de restrições: O Gargalo de escala muda de lugar, maquinas (load balancer) -> banco de dados (aurora, elastic) -> apis terceiras (DDOS Block) -> Com comunicação assíncrona isso é solucionado.
- Independência entre os serviços -> Micro serviços adicionam mais pontos de falhas que o monólito, se a comunicação for síncrona, a dependência vai existir. Porém, se for assíncrono essa dependência diminui.
- Disponibilidade -> Micro serviço diminui a disponibilidade
- Tolerância à falhas -> Circuit Breaker (disjuntor) para barrar transações para não ter processamentos ativos na hora de deployments.
- Resiliência -> é a capacidade de manter o funcionamento e se recuperar de falhas
Quais são as vantagens e desvantagens em ter uma arquitetura de microservices?
Vantagens
- Diversidade tecnológica
- Melhor controle sobre o débito técnico
- Facilidade em acompanhar a evolução tecnológica (por conta de uma base de código menor) Fazendo uma boa modelagem estratégica:
- Divisão da complexidade
- Equipes menores
- Reuso
Desafios
- Transações distribuídas
- Dificuldade em tratar e dignosticar erros
- Complexidade técnica mais alta
Uma arquitetura monolítica nem sempre é ruim, muito pelo contrário! Para projetos menores com equipes pequenas, principalmente no início da construção de um produto, é a arquitetura que dá mais resultado com o menor esforço e custo de infraestrutura

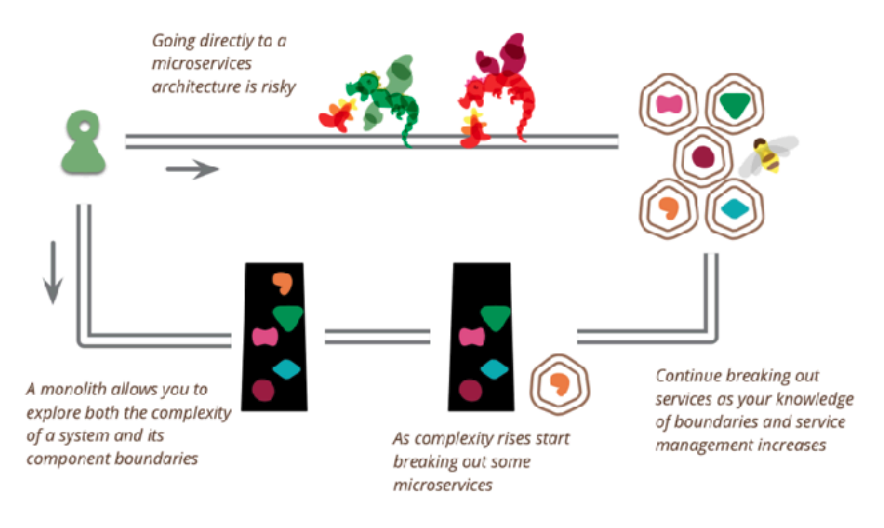
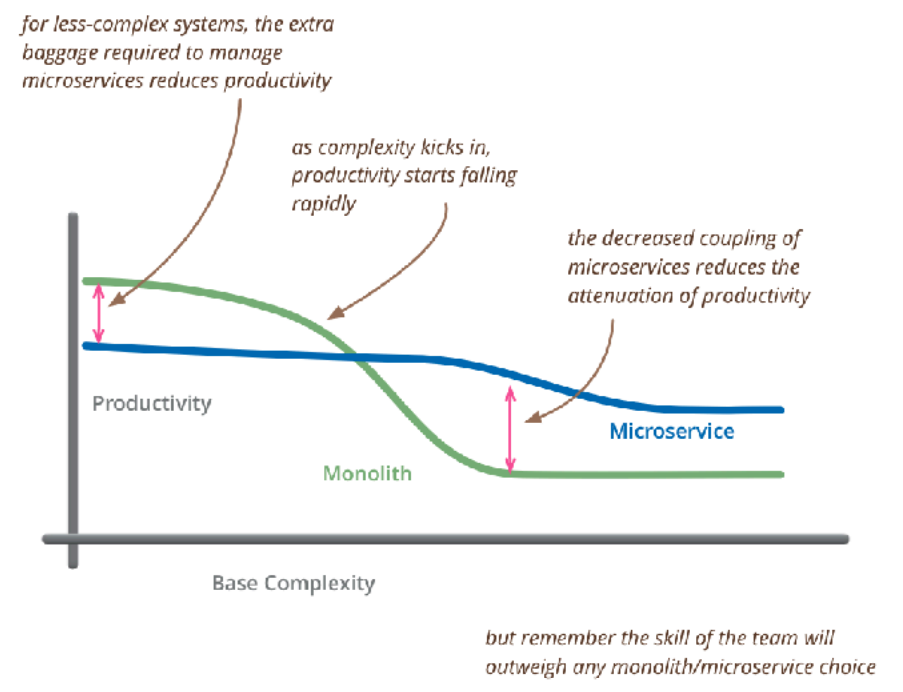
Leva tempo até entender qual é a melhor forma de dividir os bounded contexts
Consumir dados distribuídos em um ambiente de microservices
API Composition
A primeira forma é usando o padrão API Composition, ou seja, invocando cada uma das interfaces dos serviços distribuídos para obter os dados, acumulando tudo em memória.
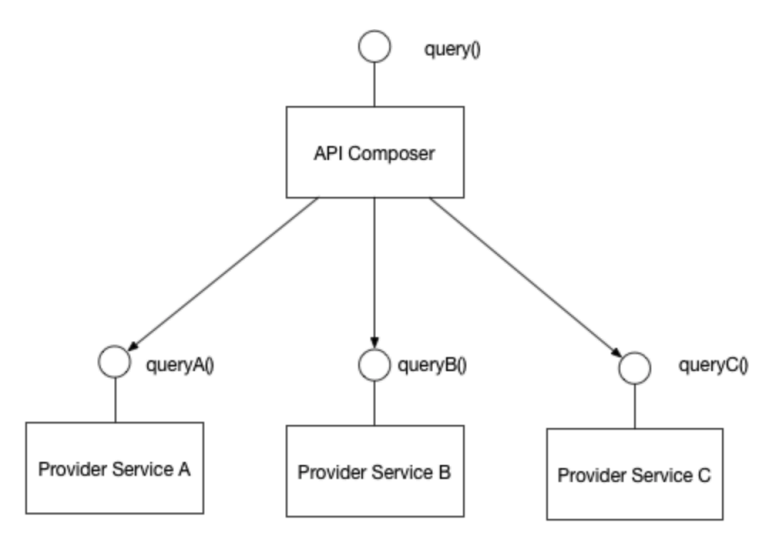
Por conta da latência envolvida na obtenção dos dados de cada serviço o tempo de resposta pode ser alto, além do consumo de memória elevado (fica mais tempo com o dado em memória);
Além do problema com os recursos, nem sempre as queries disponíveis são adequadas, por exemplo, como fazer para retornar os 10 motoristas que mais faturaram em 2022? Seria necessário solicitar ao serviço de pagamento e depois consultar o motorista pelo driverId, um por um, no serviço de conta.
CQRS
Outra forma é o CQRS, ou Command Query Responsibility Segregation, foi muito divulgado por Greg Young e envolve separar o modelo de dados de mutação do modelo de dados de consulta. Ao invés de normalizar o dado a cada consumo, criamos uma projeção do dado já formatado a cada escrita para poder ser consumido várias vezes.
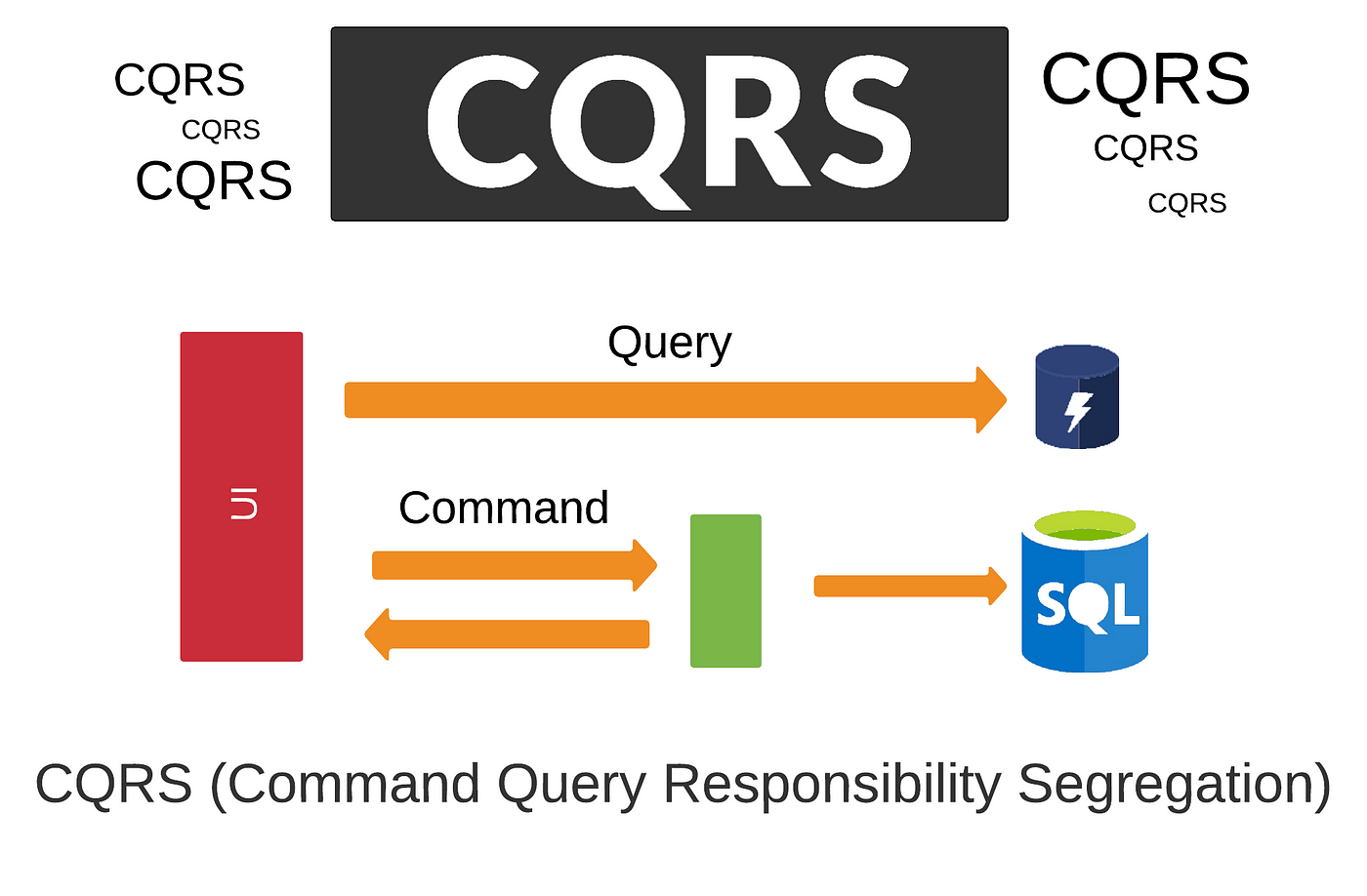
"Because the term command is widely used in other contexts I prefer to refer to them as modifiers, you also see the term mutators" - Martin Fowler
Ou seja, o modelo de dados de mutação pode e muitas vezes deve ser diferente do modelo de dados de consulta, consulta e leitura são coisas diferentes.
Ao usar CQRS com DDD e repositories, cada repository lida com um aggregate. Como aggregates devem ser pequenos, pode ser necessário buscar dados de múltiplos aggregates para responder a uma consulta. Isso pode ser complexo.
Em um cenário distribuído, os dados também estão distribuídos. Obter dados relacionados de diferentes fontes agrega complexidade.
De modo geral:
- Mantenha aggregates pequenos
- Evite muitas sobrecargas em repositories
- Consolide dados de múltiplas fontes na camada de query/leitura
- Separe queries complexas da escrita, usando CQRS
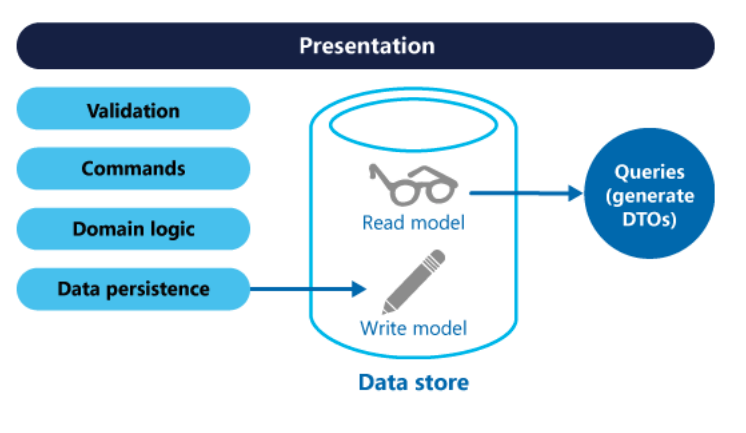
Podemos ter um mesmo banco de dados para leitura e escrita:
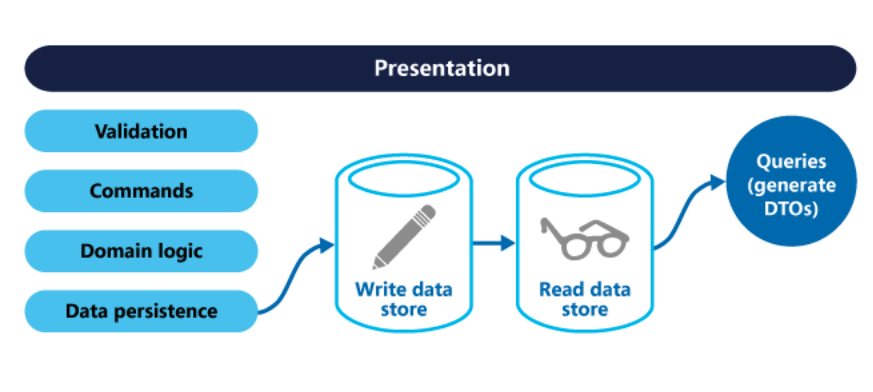
Ou podemos ter uma réplica do banco somente para leitura:
Um outro tipo de cenário envolve microservices ou tipo de ambiente com dados distribuídos. Podemos consolidar os dodos em uma base separada por meio de eventos para ser servida para consulta.
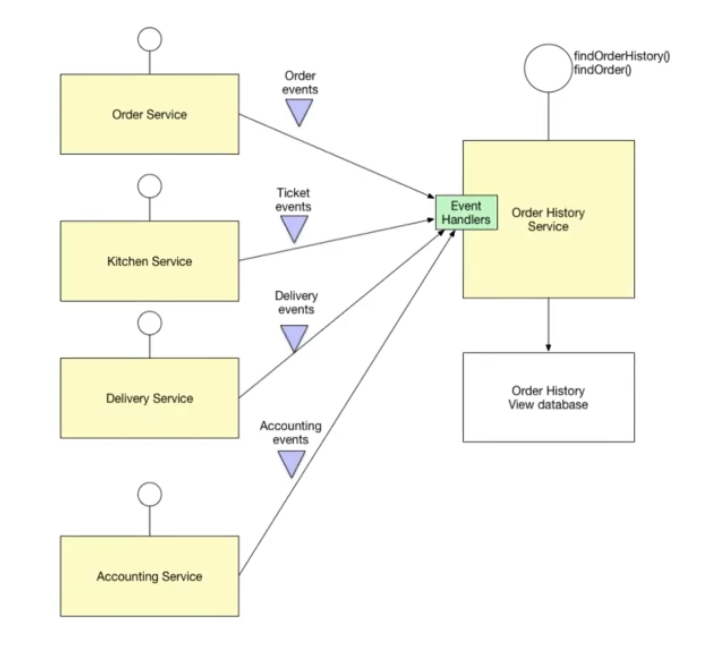
Event Driven Architecture
Transação
Transação é a abstração de um conjunto de operações que devem ser tratada como uma única unidade lógica, onde para ter sucesso, todas as suas operações devem ser bem sucedidas ou serem desfeitas
Uma forma comum de pensar em uma transação é pelo conceito de ACID ou Atomicity, Consistency, Isolation e Durability, relacionado a comandos executados em um banco de dados relacional
Por exemplo, imagine uma transação que faz uma transferência de fundos entre duas contas bancárias:
begin
insert into bank.transaction (id, type, amount) values (1, 'debit', 100);
insert into bank.transaction (id, type, amount) values (2, 'credit', 100);
commit
O que acontece se o primeiro insert tiver sucesso e o segundo falhar? Rollback
Unit of Work: Temos vários repositórios e queremos criar um contexto transacional em torno de todos eles para dar rollback em caso de erro. Esse contexto vai guardar as queries para executar no final da transação.
Porém, se nem todas as operações de uma transação são realizadas dentro do banco de dados?
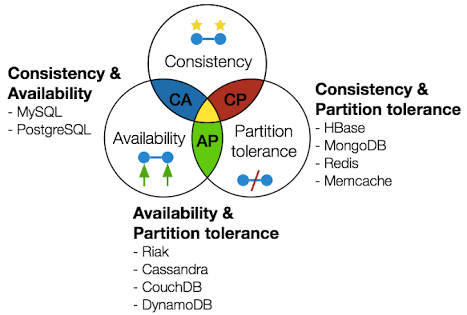
CAP Theorem
Impossível ter as três coisas:
-
Consistencia
-
Disponibilidade
-
Particionamento
-
AC: Sem particionamento, os dados estão consistentes e disponíveis
-
AP: Com particionamento, ao optar pela disponibilidade, se a conexão entre os nodos cair, perdemos consistência
-
CP: Com particionamento, ao optar pela consistencia, se a conexão entre os nodos cair, perdemos disponibilidade Existem muitas operações independentes, que podem ou não ser distribuídas em serviços diferentes.
Quanto mais complexa e distribuída for a arquitetura, maiores são as chances de alguma coisa dar errado e a resiliência é a capacidade de manter o funcionamento e se recuperar de falhas.
Como lidar com transações de forma resiliente?
É possível adotar padrões como Retry, Fallback ou até mesmo SAGA
- Retry simplesmente realiza uma ou mais retentativas em um pequeno intervalo de tempo, elas podem resolver problemas simples como perda de pacotes, oscilações na rede e até mesmo um deploy fora de hora;
- Fallback ao se deparar com uma indisponibilidade faz a tentativa em outro serviço, por exemplo, um grande e-commerce deve trabalhar com diversos adquirentes de cartão de crédito para evitar indisponibilidades e até mesmo bloqueios;
- SAGA é responsável pelo gerenciamento de uma transação de longa duração por meio de uma sequência de transações locais. Não são necessariamente relacionadas a microservices, foram criadas em 1987 e podem ser aplicadas em qualquer tipo de transação distribuída de longa duração.
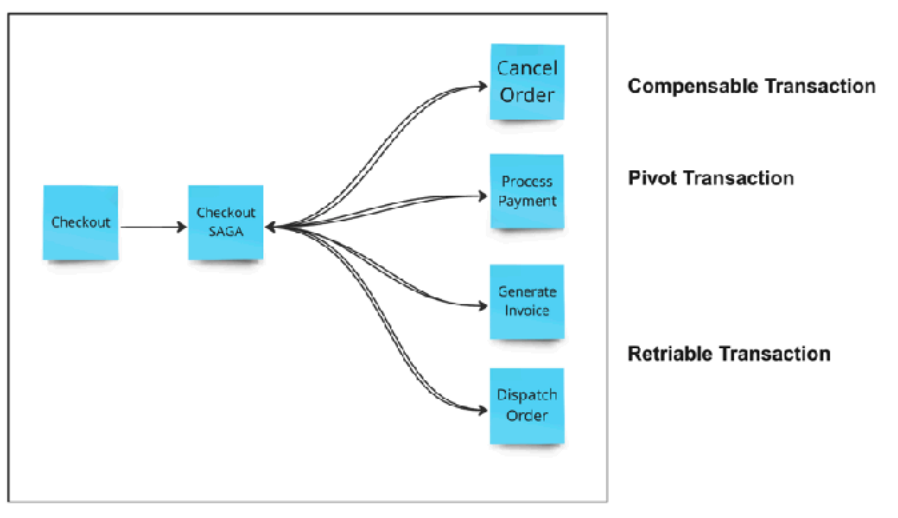
Tipos de Transação
- Pivot Transaction: São transações go/no go, ou seja, a partir delas é decidido se o fluxo de execução segue em frente ou é abortado; - Compensable Transaction: São transações para desfazer ações caso a transação toda seja abortada; - Retriable Transaction: Tem uma garantia de execução e podem se recuperar de uma possível falha ou indisponibilidade;
Tipo de Sagas
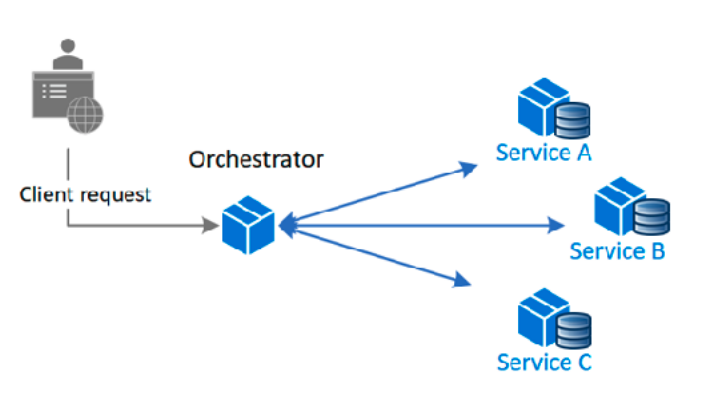
Orquestrado: existe uma lógica centralizada que faz a coordenação de cada um dos passos (maquina de status).
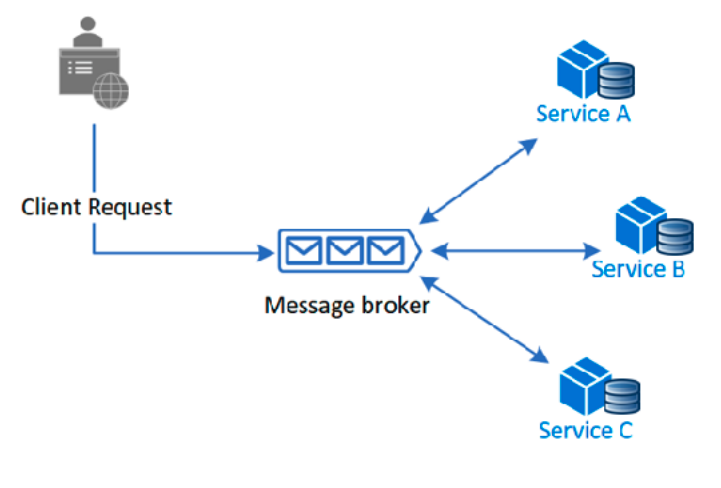
Coreografado: cada participante publica e trata eventos de forma independente, decidindo como realizar a sua parte.
Transactional Outbox
O message Broken pode ser um ponto de falha na arquitetura dirigida por eventos, por isso temos uma estratégia de transactional outbox, ao invés de tentar uma ação direta não-atômica (publicação do evento/mensagem), devemos utilizar operações atômicas (escrita em banco) que posteriormente nos permitam a execução da ação desejada.
Evento
Os eventos são fatos que aconteceram no domínio e que podem ser um gatilho para a execução de regras de negócio. Exemplos:
- OrderPlaced
- PaymentApproved
- InvoiceGenerated
- RideRequested
- RideEnded
- PositionUpdated
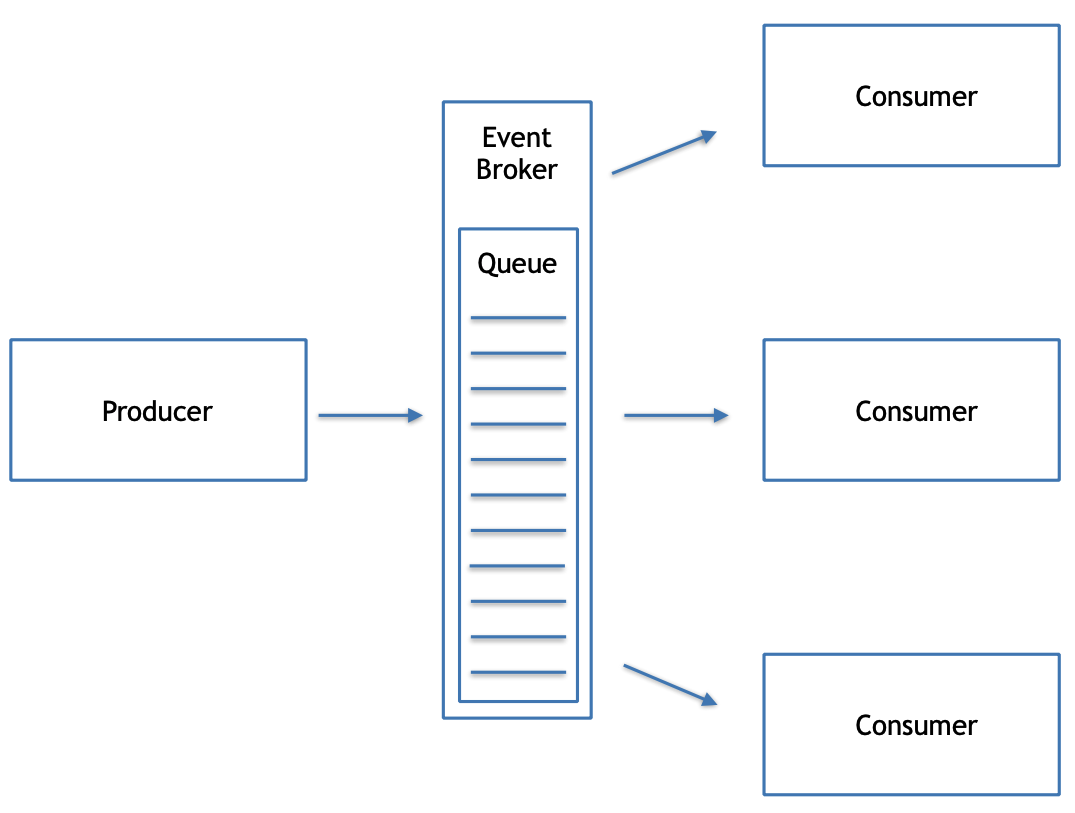

Porque a fila é necessária?
Não existem recursos suficientes disponíveis. Seria muito caro ter recursos para atender a todos de forma imediata. Em diversos momentos, por conta da ociosidade, eles seriam desperdiçados.
Como fazer a implementação das filas?
Localmente por meio de um intermediário que implementa um mecanismo de notificação Os algoritmos geralmente são baseados nos padrões Observer e Mediator Pela rede por meio de uma plataforma de mensageria Alguns tipos de plataformas de mensageria
- RabbitMQ
- Kafka
- AWS SQS
- ActiveMQ
- Google Pub/Sub
- ZeroMQ
- Pulsar
Adotar uma arquitetura orientada a eventos tem os seguintes benefícios
- Baixo acoplamento entre os use cases dentro e fora de um serviço
- Tolerância a falha com capacidade para retomar o processamento do ponto onde parou
- Melhor controle sobre o débito técnico
- Disponibilidade e escalabilidade mais alta
- Menos custos com infraestrutura (você adiciona mais maquinas porém elas podem ser menores)
- Melhor entendimento sobre o que aconteceu, inclusive com a possibilidade de PITR (Point in Time Recovery)
Adotar uma arquitetura orientada a eventos tem os seguintes desafios
- Complexidade técnica mais alta
- Lidar com a duplicação de eventos
- Falta de clareza no workflow
- Dificuldade em tratar e diagnosticar erros
Comando
Qual é a diferença entre comando e evento? Enquanto o evento é um fato, que você precisa decidir como lidar, o comando é uma solicitação, eventualmente ela pode ser rejeitada
Os nomes dos comandos são sempre no imperativo • PlaceOrder PayInvoice • GenerateReport • EnrollStudent • UpdateCustomer • UploadFile • RequestRide • UpdatePosition
O padrão command handler envolve justamente separar uma solicitação que antes era síncrona em duas etapas, uma que recebe o comando e a outra que processa o comando. Normalmente aplicada no controller, ao receber uma request, disparamos um comando.
Producer
import amqp from "amqplib";
async function main () {
const connection = await amqp.connect("amqp://localhost");
const channel = await connection.createChannel();
channel.assertQueue("test", { durable: true });
const input = {
rideId: "1234566789",
fare: 10
}
channel.sendToQueue("test", Buffer.from(JSON.stringify(input)));
}
main();
Consumer
import amqp from "amqplib";
async function main () {
const connection = await amqp.connect("amqp://localhost");
const channel = await connection.createChannel();
channel.assertQueue("test", { durable: true });
channel.consume("test", function (msg: any) {
console.log(msg.content.toString());
channel.ack(msg);
});
}
main();
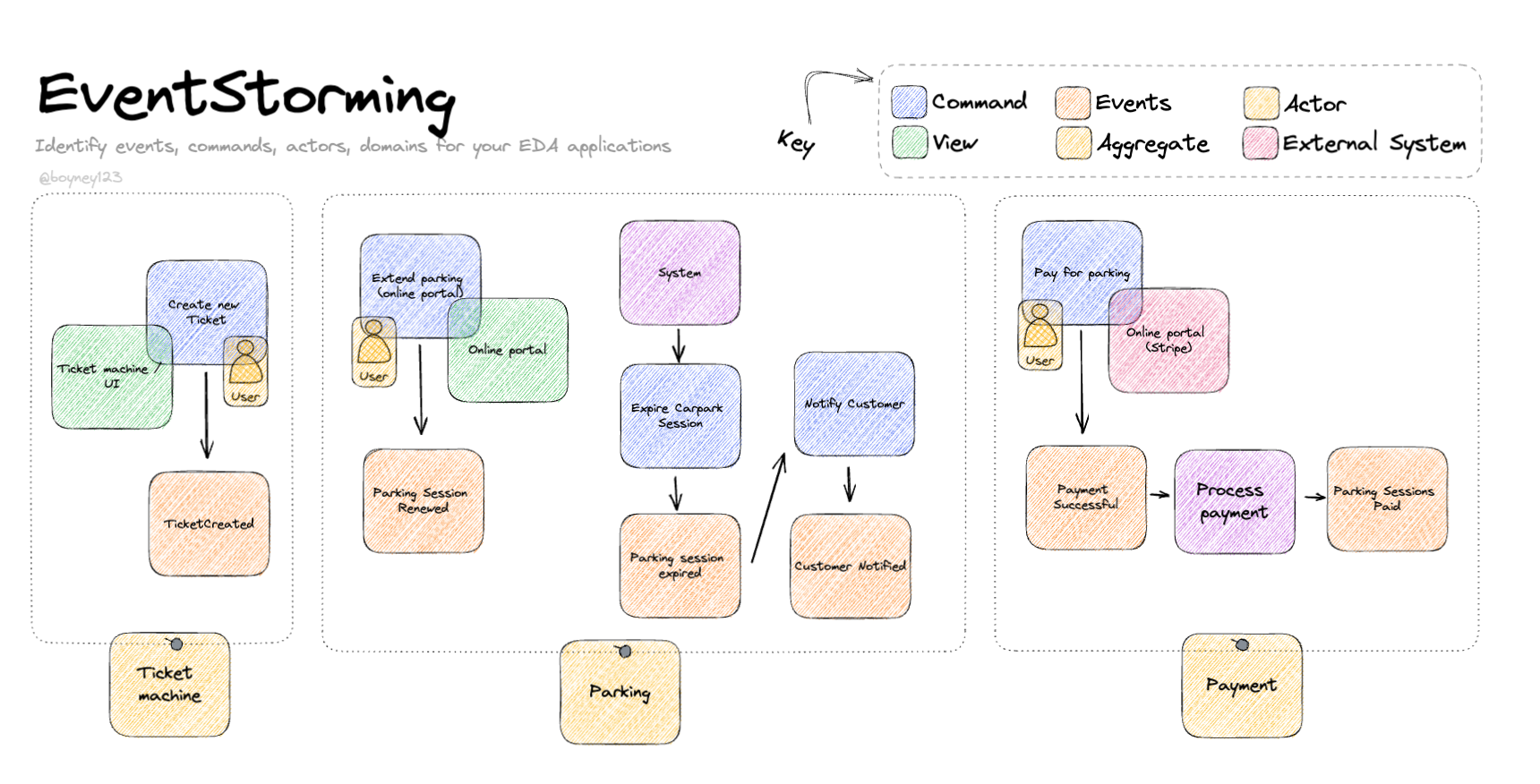
Event Storming
Event Storming é uma técnica de design colaborativo usada para mapear processos de negócio complexos. Os principais elementos do Event Storming são:
- Eventos: coisas que aconteceram no domínio. São nomeados com verbos no passado (ex: PagamentoRealizado, ClienteCadastrado).
- Comandos: ações ou eventos desejados que ainda não aconteceram. Também nomeados com verbos (ex: EfetuarPagamento, CadastrarCliente).
- Agregados: um cluster de dados relacionados a uma entidade ou objeto de valor (Customer, Payment).
Na sessão de Event Storming, os membros de uma equipe se reúnem e colaboram para mapear:
- Eventos que ocorrem no processo
- Os comandos que causam os eventos
- Os agregados envolvidos nesses eventos
O objetivo é alinhar o entendimento sobre um domínio complexo e identificar pontos problemáticos ou obscuros no processo.
O resultado é um mapa visual das sequências e fluxos de eventos no sistema. Isso ajuda a extrair requisitos e impulsionar discussões valiosas entre equipes de negócio, desenvolvimento e outras partes interessadas.