Banco de Dados


SQL
Stored Procedure, que traduzido significa Procedimento Armazenado, é um conjunto de comandos SQL que podem ser executados de uma só vez, como em uma função. Ele armazena tarefas repetitivas e aceita parâmetros de entrada para que a tarefa possa ser executada de acordo com a necessidade individual.
Uma Stored Procedure pode reduzir o tráfego de rede, melhorar o desempenho do banco de dados, criar tarefas agendadas, reduzir riscos, criar rotinas de processamento, etc.
Por todas essas e outras funções, as stored procedures são extremamente importantes para DBAs e desenvolvedores.
Existem alguns tipos básicos de procedures que podemos criar:
-
Procedures Locais - São criadas a partir de um banco de dados no próprio banco de dados do usuário;
-
Procedures Temporárias - Existem dois tipos de procedures temporárias: Locais, que devem começar com # e Globais, que devem começar com ##;
-
Procedures de Sistema - Armazenadas no banco de dados padrão do SQL Server (Master), podemos identificá-las com a sigla sp, que se origina de stored procedure. Tais procedures executam tarefas administrativas e podem ser executadas a partir de qualquer banco de dados.
-
Procedures Remotas - Podemos usar Consultas Distribuídas para tais procedures. São usadas apenas para compatibilidade.
-
Procedures Estendidas - Diferentemente das procedures já mencionadas, este tipo de procedure recebe a extensão .dll e é executada fora do SGBD SQL Server. São identificadas com o prefixo xp.
-
Procedures CLR (Common Language Runtime) - permitem que código .NET seja incorporado em procedures SQL.
Sistema de Gerenciamento de Banco de Dados (SGBD)
Sistema de Gerenciamento de Banco de Dados (SGBD), ou em inglês Database Management System (DBMS), é um conjunto de softwares utilizados para gerenciar um banco de dados, responsável por controlar, acessar, organizar e proteger as informações de uma aplicação, tendo como principal objetivo gerenciar os bancos de dados utilizados por aplicações clientes e remover essa responsabilidade delas.
Existem diversos SGBDs que utilizam SQL, como Oracle, MySQL, PostgreSQL, SQL Server, etc. Cada um com suas particularidades.
O ANSI SQL define uma linguagem padrão que permite maior portabilidade entre SGBDs.
DDL e DML
DDL e DML são tipos de linguagem SQL.
-
DDL: Data Definition Language (Linguagem de Definição de Dados), apesar do nome não interage com os dados em si, mas com os objetos do banco de dados.
-
Comandos deste tipo são CREATE, ALTER e DROP.
-
DML: Data Manipulation Language (Linguagem de Manipulação de Dados), interage diretamente com os dados dentro das tabelas.
-
Comandos DML são INSERT, UPDATE e DELETE.
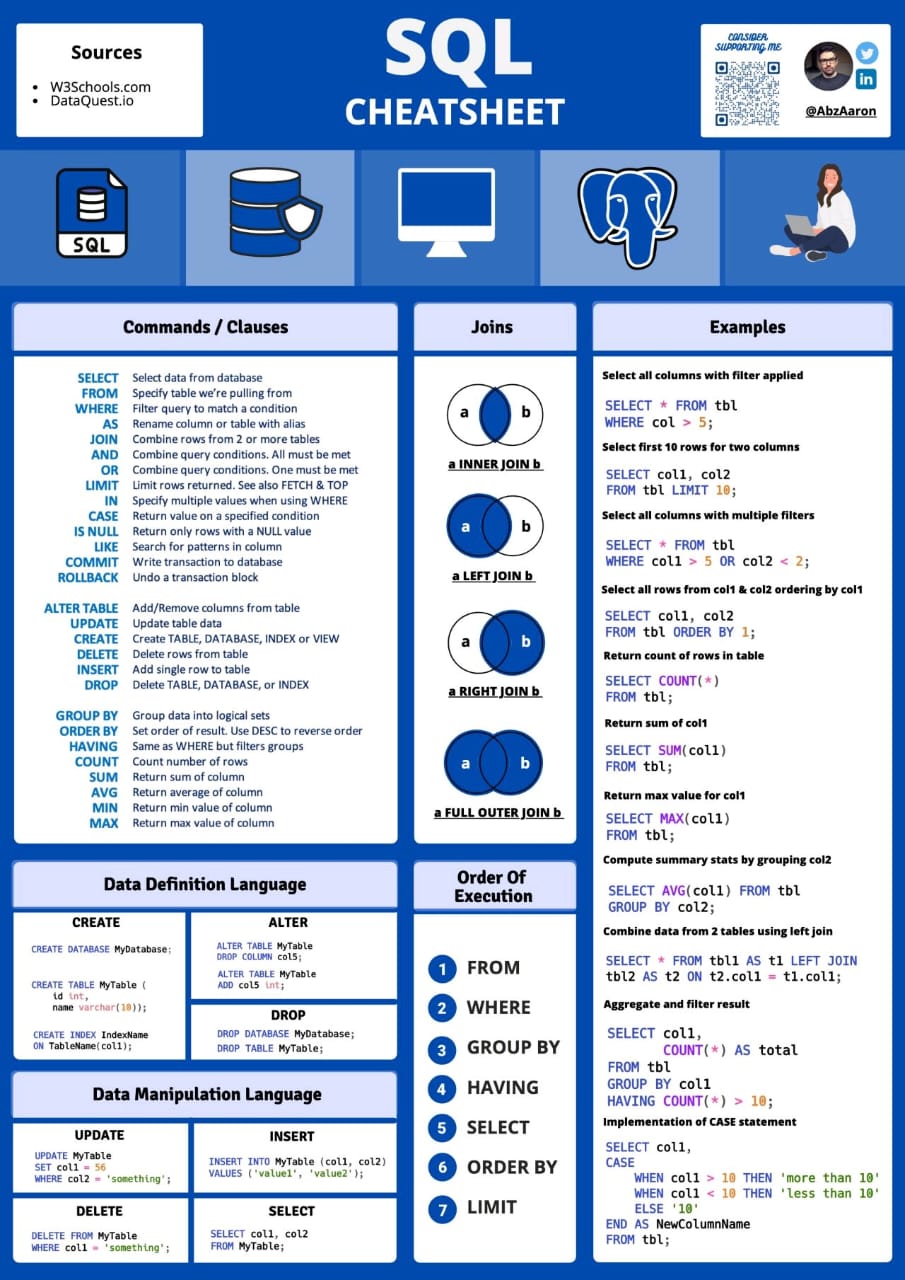
-- Listar Tabelas: adicionando \G no final lista o resultado em linhas
SHOW TABLES;
-- LIMIT OFFSET COUNT
SELECT * FROM plays LIMIT 10 OFFSET 0;
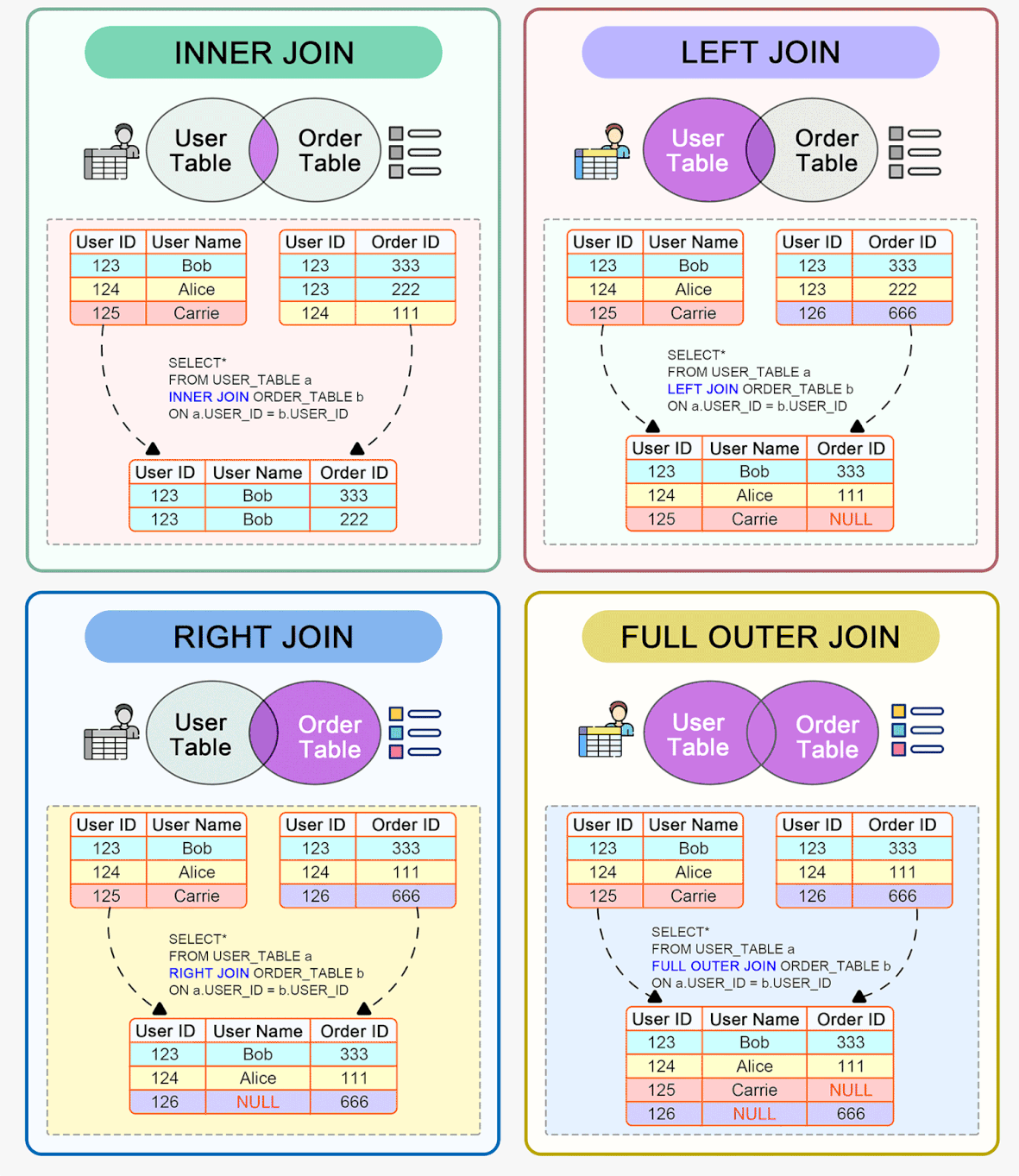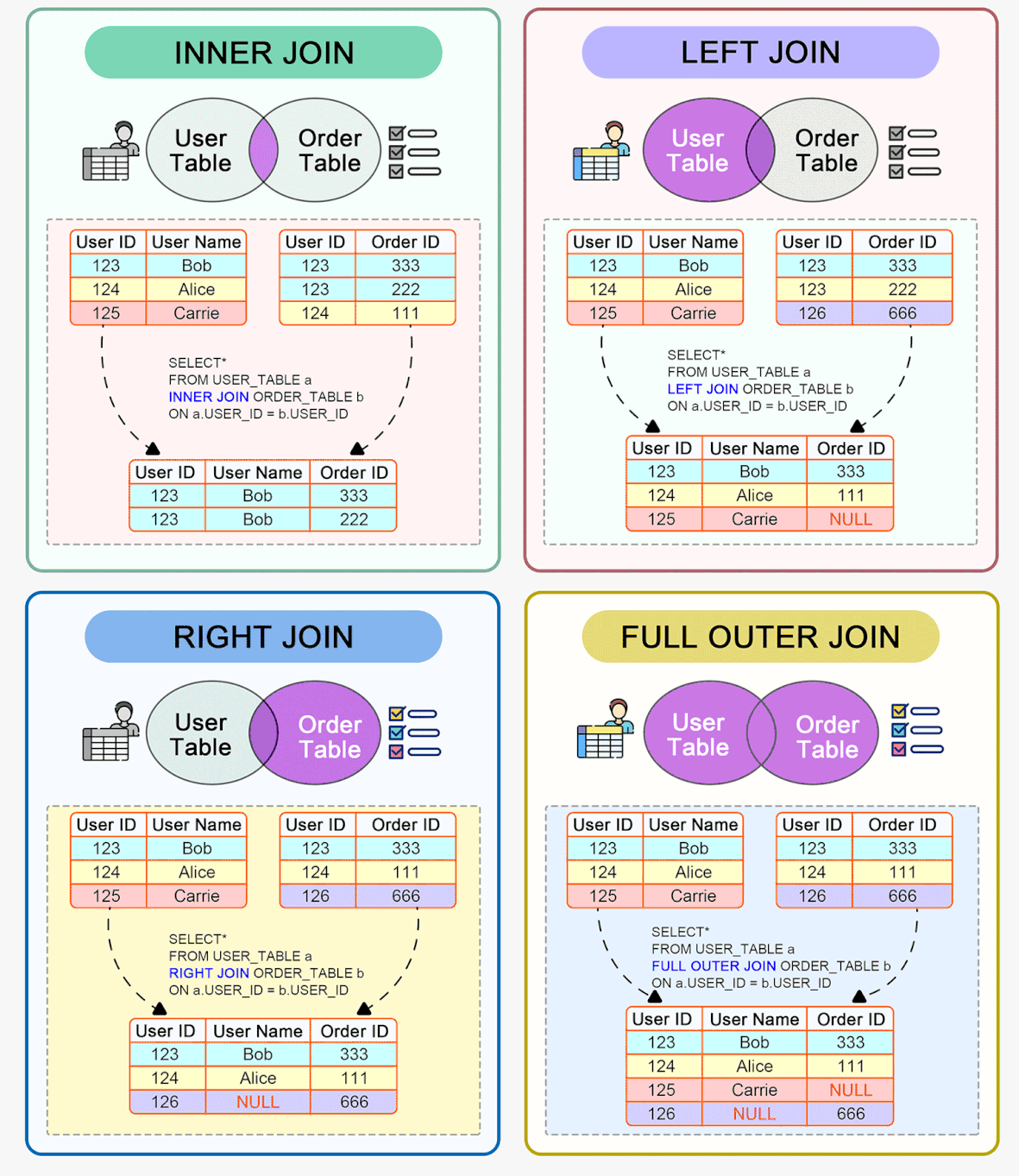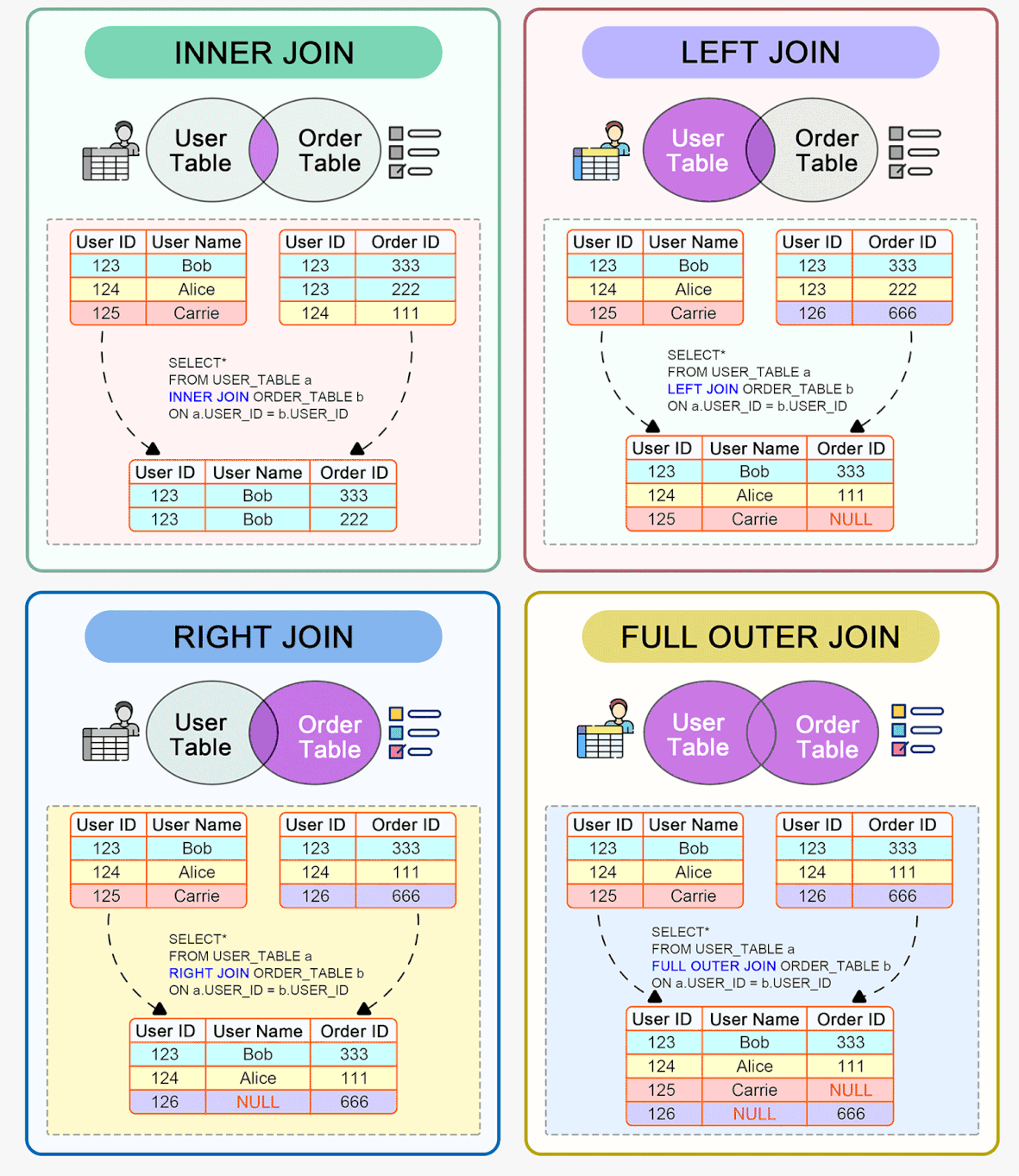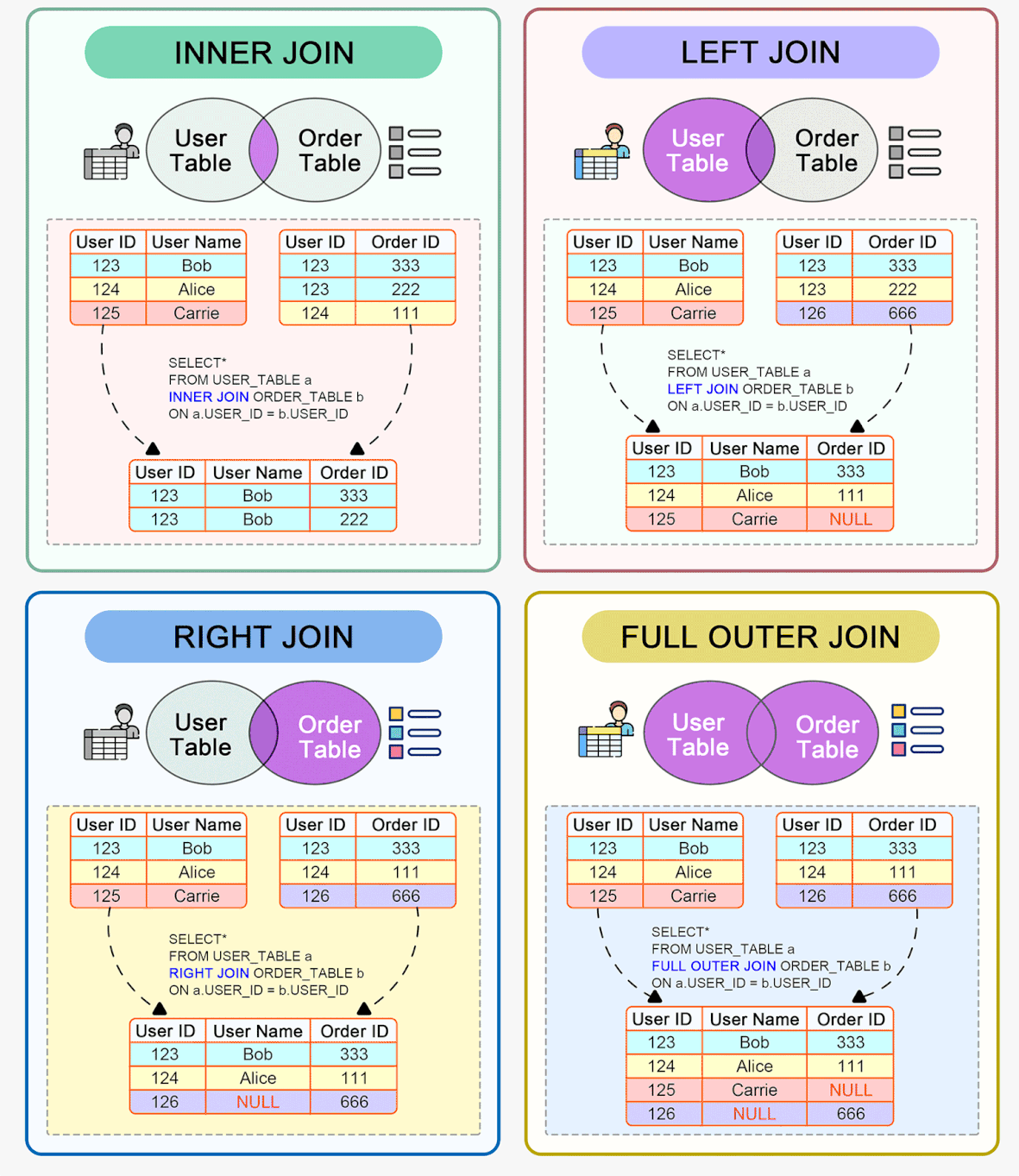
SELECT plays.id, plays.title, SUM(COALESCE(reservations.number_of_tickets,0))
FROM plays
INNER JOIN reservations ON plays.id=reservations.play_id
GROUP BY plays.id, plays.title
ORDER BY reservations.number_of_tickets ASC, PLAYS.ID DESC
LIMIT 5 OFFSET 10;
-- Deletar Linha
DELETE FROM table_name WHERE condition;
DELETE FROM TIPO_FORMA_PAGAMENTO
WHERE ID_FORMA_PAG IN (12, 13, 14);
-- Deletar Tabela
DROP TABLE table_name;
DROP TABLE employees;
-- Deletar dados da tabela
DELETE FROM employees;
TRUNCATE TABLE employees;
-- Descrever dados da tabela
DESCRIBE table_name;
DESCRIBE employees;
-- Desabilitar chave estrangeira
-- Você pode desabilitar e reabilitar as restrições de chave estrangeira
-- antes e depois de deletar
ALTER TABLE CONTABANCO_MOV NOCHECK CONSTRAINT ALL;
DELETE FROM MyTable;
ALTER TABLE MyOtherTable CHECK CONSTRAINT ALL;
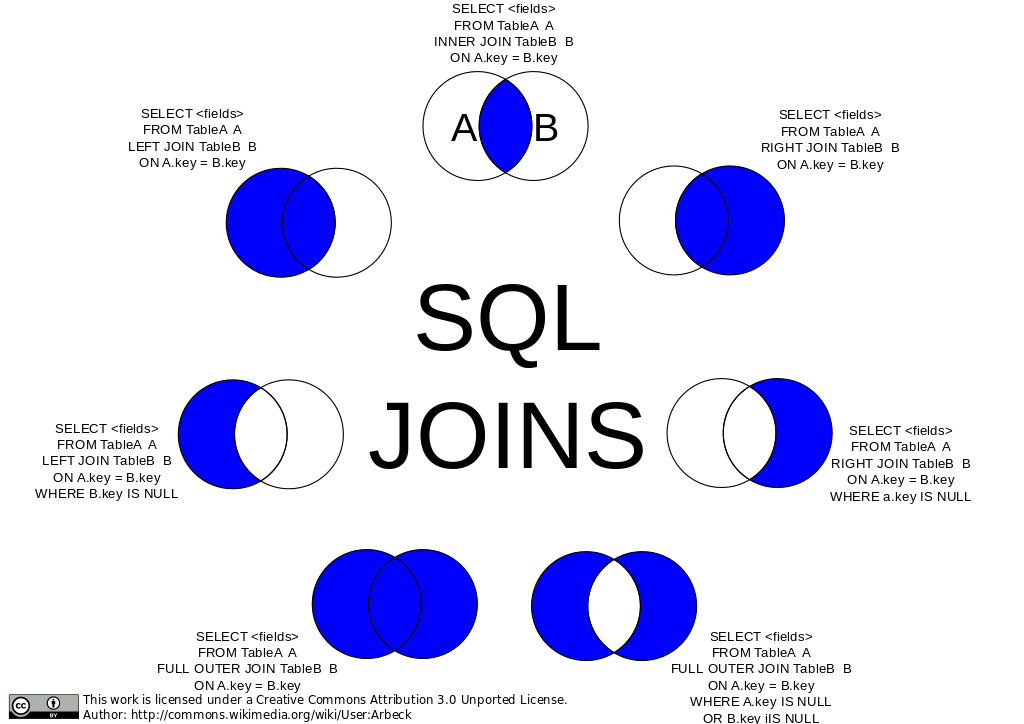
Índices
Índices são estruturas associadas às tabelas do banco de dados que permitem localizar dados de forma rápida e eficiente. Funcionam como um "índice remissivo de um livro", apontando para a localização dos dados nas tabelas.
Existem diferentes tipos de índices como primário, secundário, único, composto, clusterizado, não-clusterizado, etc.
- O índice primário, também conhecido como chave primária, é exclusivo para cada registro e geralmente usa um campo ou uma combinação de campos que identificam unicamente cada registro. É usado para garantir a integridade referencial entre tabelas.
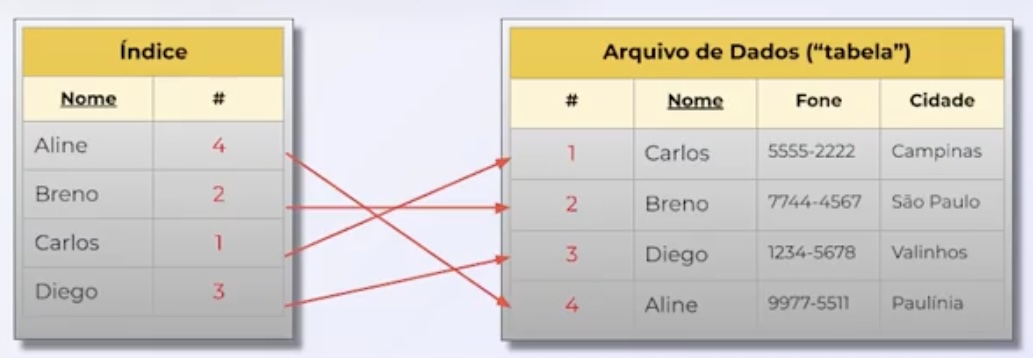
- Índices secundários, também chamados de chaves alternativas, podem conter campos duplicados e são usados para melhorar o desempenho em consultas filtradas por esses campos.
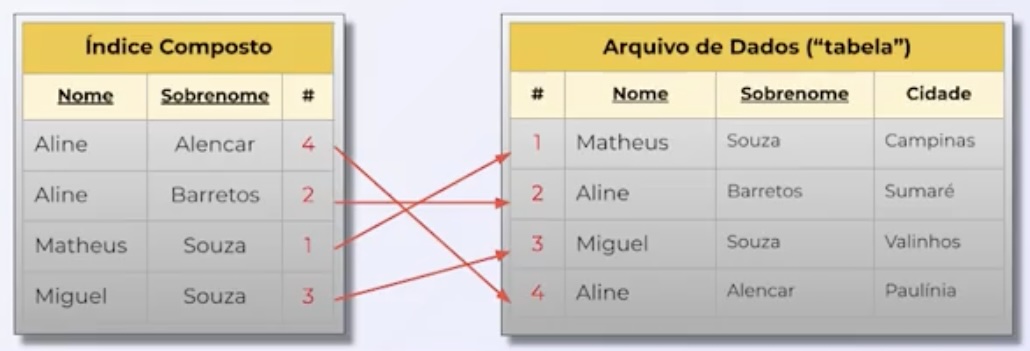
- Um índice composto contém múltiplos campos em sua definição. Isso melhora o desempenho em consultas com filtros em múltiplos campos. No entanto, possui algumas desvantagens como aumento do uso de espaço, overhead em inserções e atualizações, entre outros.
A criação de índices deve ser feita com critério, avaliando o custo-benefício para cada caso. Devem ser analisados os padrões de acesso aos dados, campos mais utilizados em filtros e joins, nível de seletividade dos campos, etc.
Índices desnecessários ou excessivos podem até degradar o desempenho, portanto seu uso deve ser otimizado. Menos às vezes é mais quando se trata de indexação de banco de dados.
Modelagem de Dados
Neste site você pode encontrar diversos exemplos de modelagem de banco de dados.
Diagrama de Classes UML
Útil para mapear objetos e seus relacionamentos. Integrável com bancos de dados ORM.
Bancos de Dados Relacionais
Um Banco de Dados Relacional é um banco de dados que modela os dados na forma de campos e tabelas com relacionamentos e integridade entre as tabelas. É controlado por um Sistema de Gerenciamento de Banco de Dados Relacional (SGBDR).
Representa tabelas, colunas, chaves e relacionamentos usando registros e chaves primárias/estrangeiras para relacionar dados. Mais próximo da implementação. Esquema e estrutura de dados predefinidos. Excelente para consultas estruturadas e transações ACID (Atomicidade, Consistência, Isolamento e Durabilidade). Exemplos: MySQL, PostgreSQL, SQL Server.
Vantagens:
- Estrutura fácil de entender
- Integridade referencial dos dados
- Dados estruturados (campos)
- Fácil de manipular (SQL)
Desvantagens:
- Requer conhecimento para criar modelagem
- Escalabilidade complexa
- Desempenho
- Escalabilidade Vertical (custo)
MySQL
MySQL é um sistema de gerenciamento de banco de dados relacional (SGBDR) open source muito popular. Algumas características principais do MySQL incluem:
- Alto desempenho, velocidade e confiabilidade comprovadas para cargas de trabalho web e servidor. Usado por muitos sites e aplicações de grande escala.
- Suporte para grandes conjuntos de dados e alto volume de consultas. Boa escalabilidade com capacidade de distribuir dados entre servidores (sharding).
- Tipos de dados flexíveis e fáceis de usar como colunas JSON. Funções para parsing e manipulação de documentos JSON.
- Uma ampla variedade de mecanismos de armazenamento como InnoDB, MyISAM, etc., atendendo a diferentes casos de uso.
- Métodos de acesso a dados do tipo SQL e NoSQL.
- Forte segurança de dados incluindo conexões SSL, gerenciamento de usuários, controle de acesso.
- Suporte multiplataforma para Linux, Windows, Mac e outros. Fácil migração entre plataformas.
- Recursos de alta disponibilidade como replicação master-slave, topologias de cluster.
- Ferramentas de tuning fornecidas para ajustar e otimizar o desempenho do banco de dados.
- Extenso ecossistema de ferramentas GUI, monitoramento, soluções de backup, etc.
Algumas limitações do MySQL incluem:
- Suporte transacional e mecanismos de integridade menos avançados comparados a bancos de dados como PostgreSQL.
- Não otimizado para cargas de trabalho analíticas mais avançadas comparado a bancos de dados colunares.
- Menos flexibilidade em alterações de esquema do banco de dados, exigindo mais tempo de inatividade para manutenção.
No geral, o MySQL se destaca em aplicações web de alto desempenho. Oferece uma ótima combinação de velocidade, escalabilidade, recursos e facilidade de uso para cargas de trabalho CRUD padrão.
MariaDB
MariaDB é um fork open source do MySQL focado em desempenho e estabilidade. Principais características:
- Mais rápido que o MySQL em benchmarks.
- Armazenamento colunar para consultas mais rápidas.
- Melhor uso de núcleos e threads modernos.
- Compatível com aplicações MySQL existentes.
Bancos de Dados Não-Relacionais
Armazenam dados em documentos flexíveis como JSON ao invés de tabelas rigidamente estruturadas. Exemplos: MongoDB, DynamoDB, Cassandra;
Vantagens:
- Esquema flexível ou inexistente; • Chave / Valor • Orientado a Grafos • Orientado a Documentos • Armazenamento Colunar
- Suporta mudanças frequentes;
- Foco em alto desempenho, escalabilidade e disponibilidade distribuída.
Desvantagens:
- Baixa consistência;
- Baixa integridade;
- Necessidade de conhecimento sobre os tipos de bancos de dados existentes;
MongoDB
MongoDB é um banco de dados NoSQL orientado a documentos muito popular para uso com Node.js. Algumas de suas principais características e aplicações com Node.js incluem:
-
Armazenamento de dados JSON - Documentos MongoDB armazenam dados em formato JSON, tornando-os muito fáceis de usar com aplicações JavaScript como Node.js. Nenhuma conversão de objetos é necessária.
-
Esquema flexível - MongoDB não possui esquema rígido, permitindo que os dados da aplicação sejam facilmente alterados e evoluídos sem precisar modificar todo o banco de dados. Isso facilita o desenvolvimento ágil.
-
Alto desempenho - MongoDB foi projetado para escalar horizontalmente em clusters para lidar com grandes volumes de dados e cargas pesadas. Integra-se bem com o modelo assíncrono e orientado a eventos do Node.js.
-
Índices Ad-Hoc - Índices podem ser adicionados dinamicamente para melhorar o desempenho de consultas, útil para dados altamente variáveis.
-
Integração - Bibliotecas populares como Mongoose fornecem fácil integração entre Node.js e MongoDB para modelagem de dados e interações com o banco de dados.
Alguns pontos negativos incluem:
-
Menor consistência de dados - MongoDB sacrifica alguma consistência de dados em favor de alta disponibilidade e desempenho. Pode ser um problema para alguns casos de uso.
-
Complexidade na modelagem de dados - Modelar dados adequadamente com documentos e coleções complexas requer experiência. É menos intuitivo que bancos de dados SQL relacionais.
-
Menos recursos de consulta - Opções de consulta e agregação de dados são mais limitadas que em bancos de dados SQL, embora essa diferença esteja diminuindo nas versões mais recentes.
O MongoDB 4.0 trouxe melhorias significativas como:
- Transações ACID multi-documento.
- Balanceamento de carga entre shards.
- Compressão de dados WiredTiger.
- Motor de armazenamento em disco criptografado.
Bancos de Dados focados em Serverless
Dynamo
DynamoDB possui:
- Backup e restauração automáticos entre regiões.
- Criptografia em repouso e em trânsito.
- Cache em memória para desempenho.
FaunaDB
FaunaDB também possui características interessantes:
- Transações ACID completas para garantir consistência e confiabilidade.
- Streaming de dados para processamento em tempo real.
- Distribuição inteligente de dados entre regiões.
- Utiliza a Fauna Query Language (FQL)
Supabase
Supabase é uma alternativa open source ao Firebase que fornece recursos como autenticação, armazenamento de dados e funções serverless para aplicações web e mobile.
Algumas vantagens importantes:
- Baseado em ferramentas comprovadas e testadas como Postgres, Auth0 e buckets de armazenamento S3.
- Interface de dashboard intuitiva para gerenciar dados e usuários.
- API RESTful CRUD automatizada.
- Bibliotecas client para dart, flutter, javascript, typescript, etc.
- Foco em segurança e privacidade de dados.
- Preços competitivos e transparentes.
Supabase fornece uma ótima maneira de prototipar e construir MVPs com back-end, autenticação e banco de dados já integrados. Também pode ser usado em produção para casos de uso menos complexos.
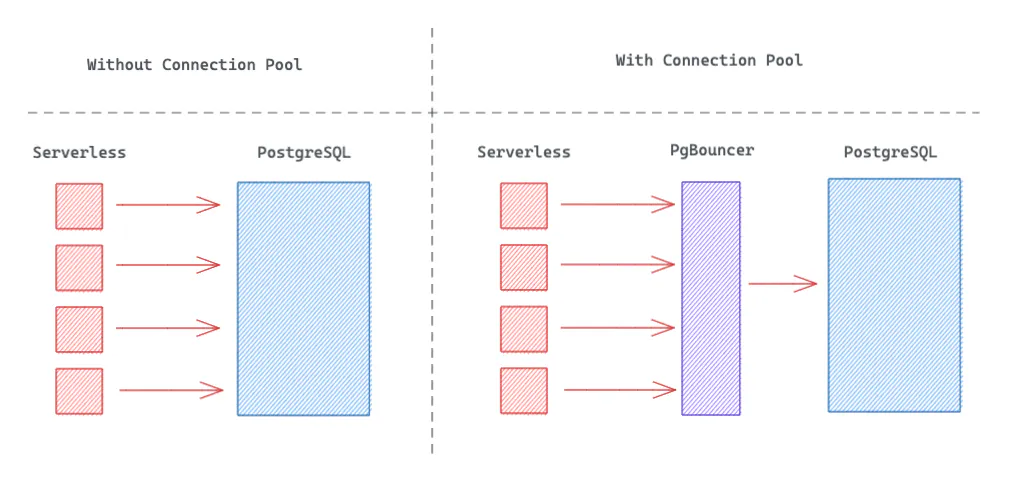
Supabase usa PgBouncer para pool de conexões. Um "pool de conexões" é um sistema (externo ao Postgres) que gerencia conexões, ao invés do sistema nativo do PostgreSQL.
Quando um cliente faz uma requisição, o PgBouncer "aloca" uma conexão disponível para o cliente. Quando a transação ou sessão do cliente é completada, a conexão é devolvida ao pool e fica livre para ser usada por outro cliente.
ORMs
Um ORM (Object-Relational Mapping ou Mapeamento Objeto-Relacional) é uma técnica de desenvolvimento que mapeia entre um banco de dados relacional tradicional e uma representação de objetos compatível com a linguagem de programação utilizada.
Alguns benefícios dos ORMs:
- Abstrai e facilita o acesso ao banco de dados mapeando tabelas para classes e registros para objetos.
- Aumenta a produtividade reduzindo a quantidade de código de acesso a dados que precisa ser escrito.
- Adiciona recursos como lazy loading, caching, eager loading para melhorar o desempenho.
Prisma:
- ORM moderno, type-safe e intuitivo para Node.js e TypeScript.
- Gera interfaces GraphQL para aplicações front-end.
- Migrations e seeds de banco de dados.
- Suporta PostgreSQL, MySQL, SQL Server, SQLite, etc.
Recursos: Migration: https://echobind.com/post/make-prisma-ignore-a-migration-change
TypeORM:
- ORM para TypeScript e JavaScript para Node.js e navegadores.
- Ênfase em validação de entidades e desempenho de migrations.
- Suporta diversos bancos de dados.
- Código e documentação muito completos.
Sequelize:
ORM Node.js que suporta PostgreSQL, MySQL, MariaDB, SQLite e MSSQL.
Hibernate:
ORM Java popular que suporta diversos bancos de dados relacionais.

Desempenho
Paginação
A paginação tradicional usando OFFSET parece simples à primeira vista:
SELECT * FROM posts
ORDER BY created_at DESC
OFFSET 20 LIMIT 10;
No entanto, essa abordagem tem dois grandes problemas:
-
Problemas de Desempenho: O banco de dados precisa buscar e descartar todas as linhas antes do seu offset. Se você está na página 100, ele processa 1000 linhas só para mostrar 10!
-
Inconsistência de Dados: Considere este cenário:
- Usuário carrega a página 1 (linhas 1-10)
- Novo post é criado
- Usuário carrega a página 2 (linhas 11-20)
- O novo post empurrou tudo para baixo, causando:
- Conteúdo duplicado
- Conteúdo pulado
Paginação por Keyset
A paginação por keyset (também chamada de paginação baseada em cursor) resolve esses problemas usando os valores do último item para buscar a próxima página:
SELECT * FROM posts
WHERE created_at < :last_seen_timestamp
ORDER BY created_at DESC
LIMIT 10;
Benefícios
- Melhor Desempenho: Sem processamento desperdiçado de linhas puladas
- Consistência: Novos itens não afetam a paginação
- Perfeito para Scroll Infinito: Encaixe natural para funcionalidade "Carregar Mais"
Limitações
- Sem Acesso Aleatório a Páginas: Não é possível pular diretamente para a página 50
- Implementação Mais Complexa: Requer rastreamento de marcadores de posição
- Múltiplas Colunas de Ordenação: Fica mais complexo com ordenação composta
Melhores Casos de Uso
- Feeds de redes sociais
- Implementações de scroll infinito
- Streams de dados em tempo real
- Navegação em grandes conjuntos de dados
Remoção Segura de Colunas em Produção
Remover uma coluna de banco de dados em um ambiente de produção com deploys rolling requer coordenação cuidadosa. Muitos ORMs (como o ORM do Django, Hibernate, Prisma) listam explicitamente cada campo do modelo nas queries SELECT, INSERT e UPDATE. Isso significa que se você remover uma coluna enquanto servidores antigos ainda estão em execução, esses servidores falharão com erros como UndefinedColumn: column does not exist.
O Problema
Em um deploy rolling:
- As migrations do banco de dados rodam primeiro
- Os servidores da aplicação atualizam um de cada vez
- Durante essa janela, servidores com código antigo coexistem com o banco de dados já migrado
Se uma migration remove uma coluna, qualquer servidor antigo que ainda referencia essa coluna vai falhar.
A Solução: Remoção de Coluna em 2 Deploys
Deploy 1 — Parar de consultar a coluna
- Remover a definição do campo/coluna do modelo ORM
- Remover todas as referências no código (serializers, queries, respostas da API)
- NÃO criar uma migration — a coluna permanece no banco de dados
- Servidores antigos ainda têm a coluna em suas queries, mas tudo bem — consultar uma coluna existente é inofensivo
Deploy 2 — Remover a coluna
- Criar e executar a migration que remove a coluna
- Todos os servidores já pararam de consultá-la desde o Deploy 1
Linha do tempo:
Deploy 1 Deploy 2
(remover do ORM) (remover do BD)
| |
Servidores antigos ───────| |
(consultam coluna) ✓ | |
| |
Servidores novos ─────────|────────────────────────|
(não consultam coluna) ✓ | Coluna existe mas | Coluna removida ✓
| não é consultada ✓ |
Adicionando uma Coluna com Segurança
O problema inverso: adicionar uma coluna NOT NULL causa erros porque servidores antigos não a incluem nas instruções INSERT.
- Sempre adicione novas colunas como
NULLprimeiro - Aplique restrições de obrigatoriedade na camada da aplicação
- Em um deploy seguinte, preencha os dados e então adicione a restrição
NOT NULL
Renomeando uma Coluna (3 Deploys)
Renomear é o mais perigoso — combina uma remoção e uma adição:
- Deploy 1: Adicionar a nova coluna como
NULL, escrever em ambas, ler da nova (com fallback para a antiga) - Deploy 2: Remover todas as referências à coluna antiga, removê-la do modelo ORM
- Deploy 3: Remover a coluna antiga via migration
Notas Específicas por ORM
| ORM | Comportamento | Detalhe Chave |
|---|---|---|
| Django | Lista todos os campos do modelo nas queries | Remover campo do models.py, adiar makemigrations |
| Prisma | Migrations dirigidas por schema | Usar prisma migrate com --create-only para adiar |
| Hibernate | Mapeia campos da entidade para colunas | Remover da classe @Entity, adiar migration Flyway/Liquibase |
| TypeORM | Sincroniza entidades com o schema | Desabilitar synchronize, gerenciar migrations manualmente |
| Sequelize | Modelo define campos das queries | Remover da definição do modelo, criar migration separadamente |
O princípio chave se aplica universalmente: desacople a mudança no código da mudança no schema, e faça o deploy na ordem correta.
Resources: https://use-the-index-luke.com/no-offset N+1 queries

