Banco de Dados


SQL
Stored Procedure, que traduzido significa Procedimento Armazenado, é uma conjunto de comandos em SQL que podem ser executados de uma só vez, como em uma função. Ele armazena tarefas repetitivas e aceita parâmetros de entrada para que a tarefa seja efetuada de acordo com a necessidade individual.\
Um Stored Procedure pode reduzir o tráfego na rede, melhorar a performance de um banco de dados, criar tarefas agendadas, diminuir riscos, criar rotinas de processamento, etc.
Por todas estas e outras funcionalidades é que os stored procedures são de extrema importância para os DBAs e desenvolvedores.
Existem alguns tipos de procedures básicos que podemos criar:
- Procedimentos Locais - São criados a partir de um banco de dados do próprio usuário;
- Procedimentos Temporários - Existem dois tipos de procedimentos temporários: Locais, que devem começar com # e Globais, que devem começar com ##;
- Procedimentos de Sistema - Armazenados no banco de dados padrão do SQL Server (Master), podemos indentificá-los com as siglas sp, que se origina de stored procedure. Tais procedures executam as tarefas administrativas e podem ser executadas a partir de qualquer banco de dados.
- Procedimentos Remotos - Podemos usar Queries Distribuídas para tais procedures. São utilizadas apenas para compatibilidade.
- Procedimentos Estendidos - Diferente dos procedimentos já citados, este tipo de procedimento recebe a extensão .dll e são executadas fora do SGBD SQL Server. São identificadas com o prefixo xp.
- Procedimentos de CLR (Common Language Runtime) - permitem que código .NET seja incorporado em procedures SQL.
Data Base Management System ou Sistema (SGBD)
Data Base Management System ou Sistema de Gerenciamento de Banco de Dados (SGBD) é um conjunto de software utilizado para o gerenciamento de uma base de dados, responsáveis por controlar, acessar, organizar e proteger as informações de uma aplicação, tendo como principal objetivo gerenciar as bases de dados utilizadas por aplicações clientes e remover esta responsabilidade das mesmas.
Existem diversos SGBDs que utilizam SQL, como Oracle, MySQL, PostgreSQL, SQL Server, etc. Cada um com suas particularidades.
O SQL ANSI define um padrão para a linguagem que permite maior portabilidade entre SGBDs.
DDL E DML
DDL e DML são tipos de linguagem SQL.
- DDL: Data Definition Language ou Linguagem de Definição de Dados, apesar do nome não interage com os dados e sim com os objetos do banco.
- São comandos desse tipo o CREATE, o ALTER e o DROP.
- DML: Data Manipulation Language, ou Linguagem de Manipulação de Dados. interage diretamente com os dados dentro das tabelas.
- São comandos do DML o INSERT, UPDATE e DELETE.
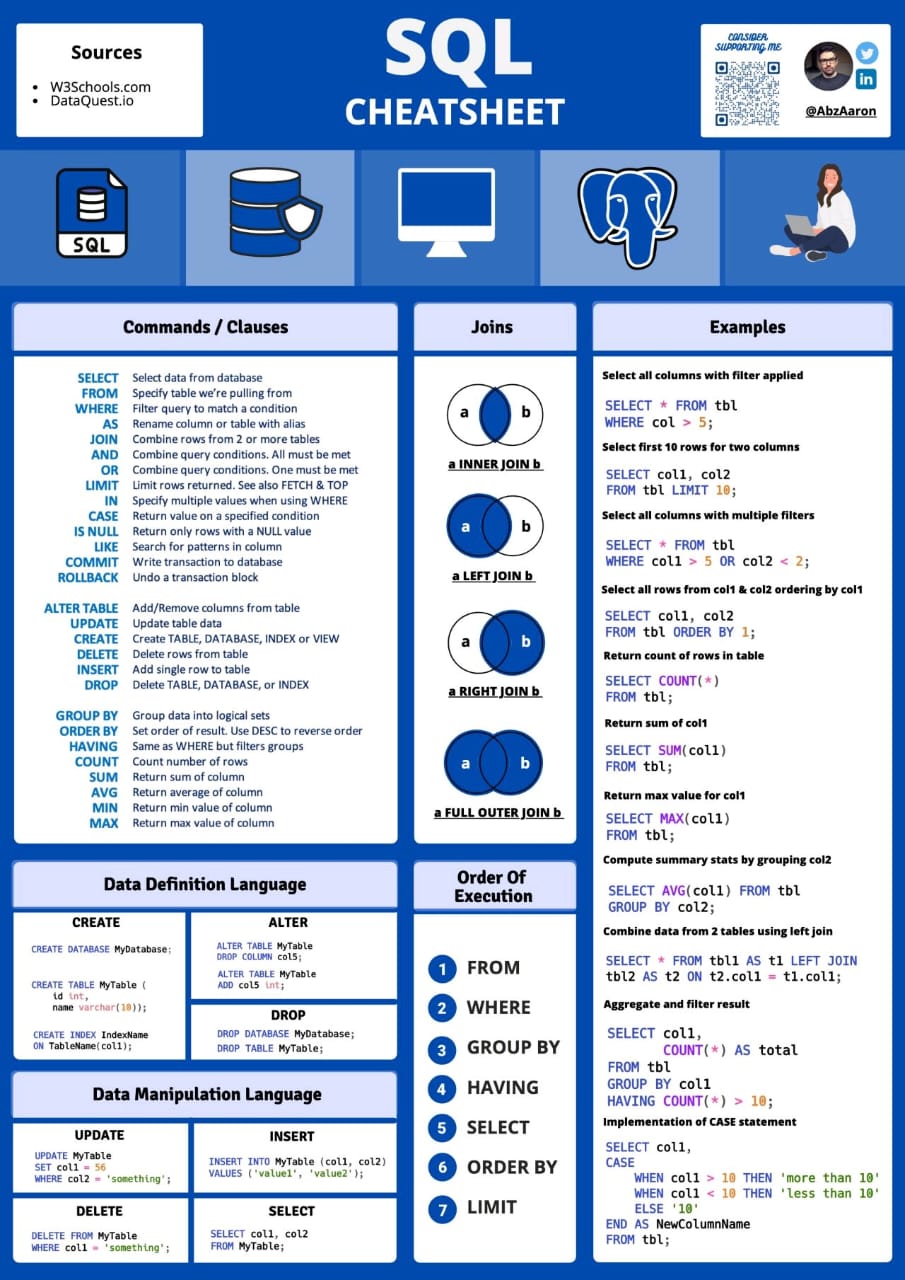
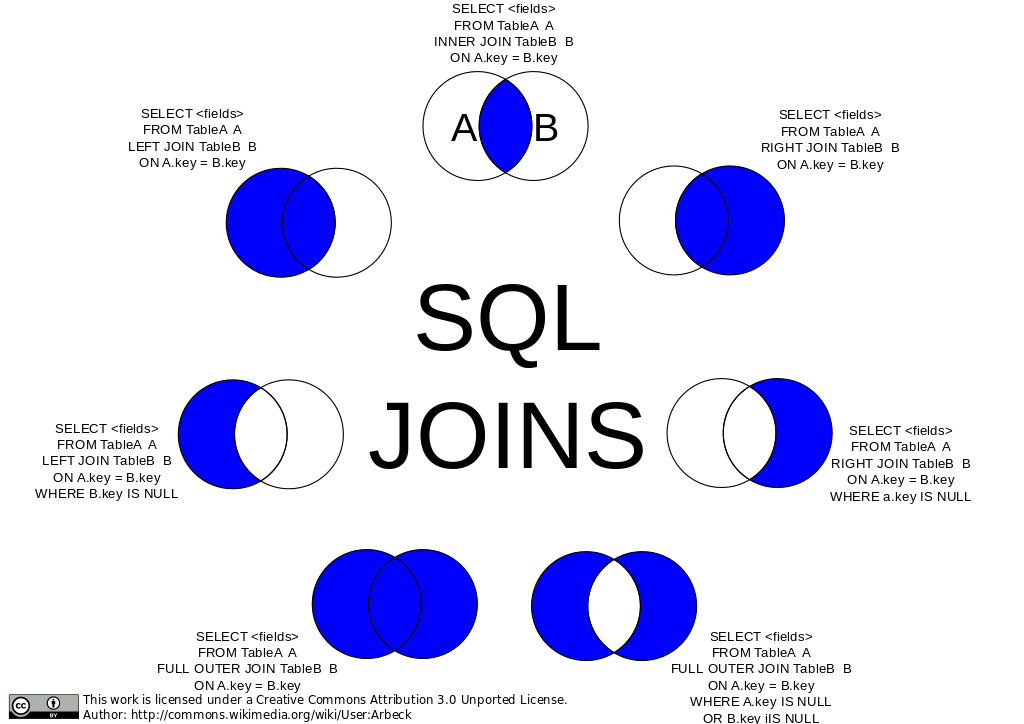
-- Listar Tabelas: adicionando \G no final lista o resultado em linhas
SHOW TABLES;
-- LIMIT OFFSET COUNT
SELECT * FROM plays LIMIT 10 OFFSET 0;
SELECT plays.id, plays.title, SUM(COALESCE(reservations.number_of_tickets,0))
FROM plays
INNER JOIN reservations ON plays.id=reservations.play_id
GROUP BY plays.id, plays.title
ORDER BY reservations.number_of_tickets ASC, PLAYS.ID DESC
LIMIT 5 OFFSET 10;
-- Deletar Row
DELETE FROM table_name WHERE condition;
DELETE FROM TIPO_FORMA_PAGAMENTO
WHERE ID_FORMA_PAG IN (12, 13, 14);
-- Deletar Table
DROP TABLE table_name;
DROP TABLE employees;
-- Deletar dados da Tabela
DELETE FROM employees;
TRUNCATE TABLE employees;
-- Descrever dados da tabela
DESCRIBE table_name;
DESCRIBE employees;
-- Desbloqueio de foreign key
-- You can disable and re-enable the foreign key constraints
-- before and after deleting
ALTER TABLE CONTABANCO_MOV NOCHECK CONSTRAINT ALL;
DELETE FROM MyTable;
ALTER TABLE MyOtherTable CHECK CONSTRAINT ALL;
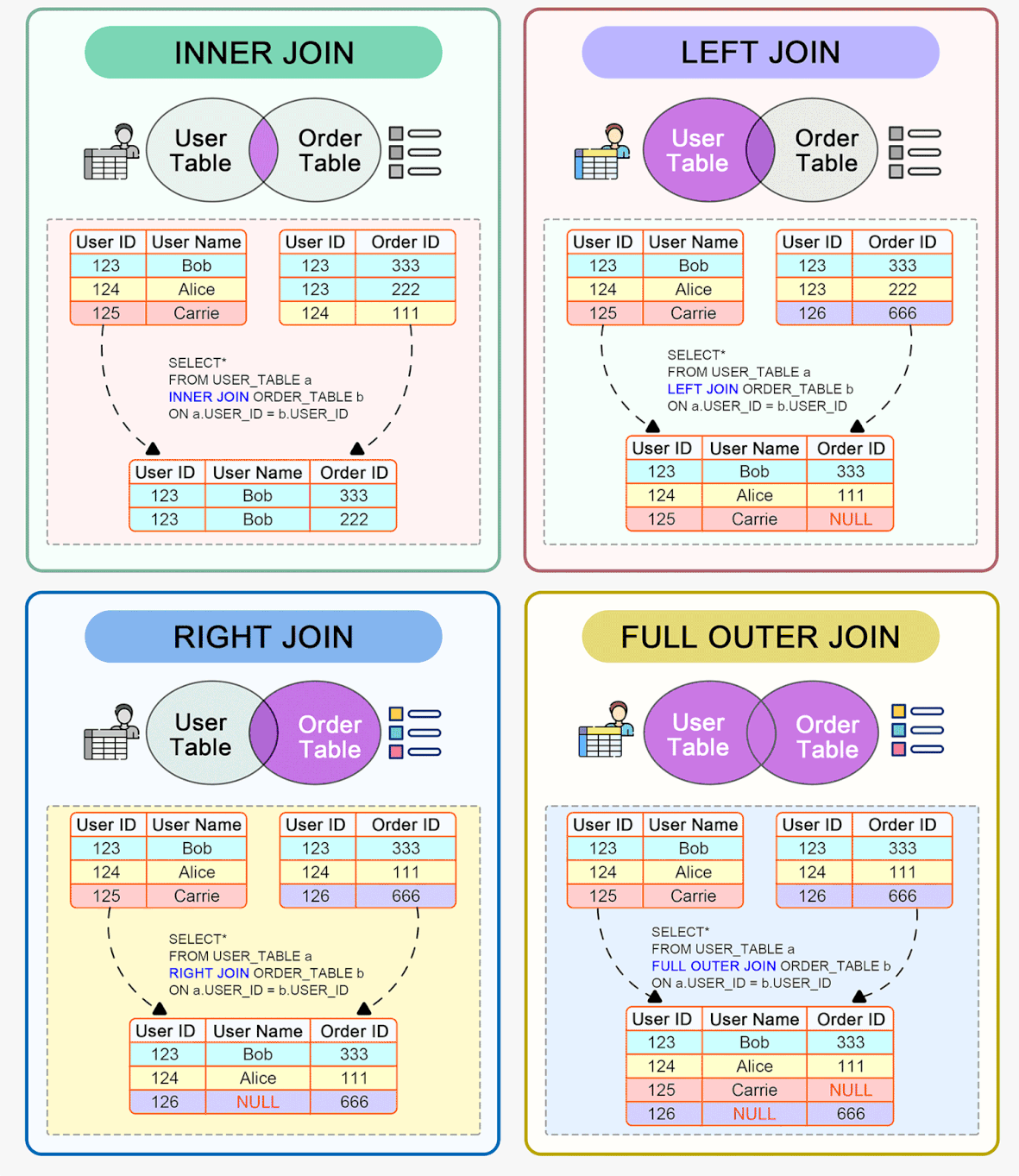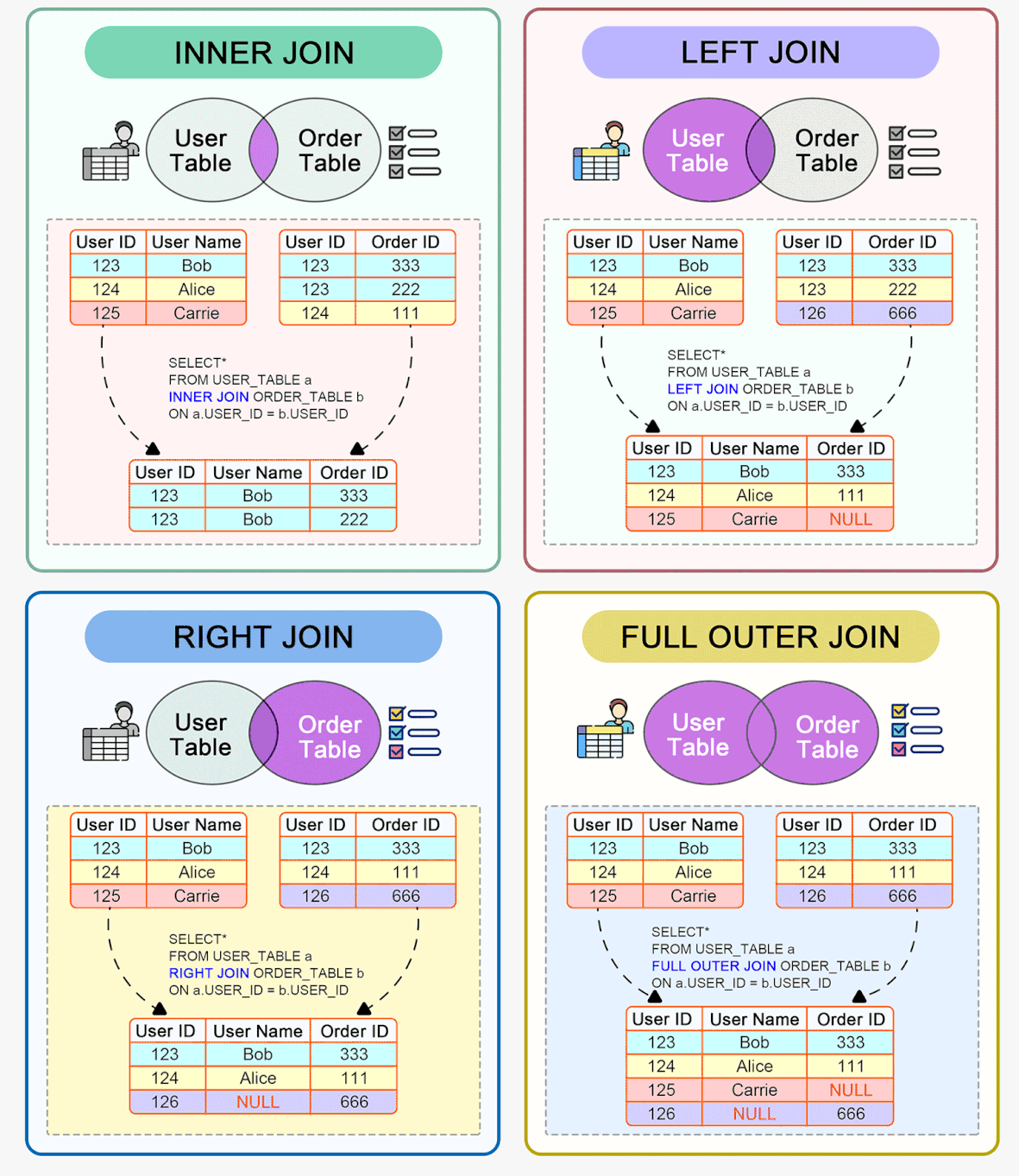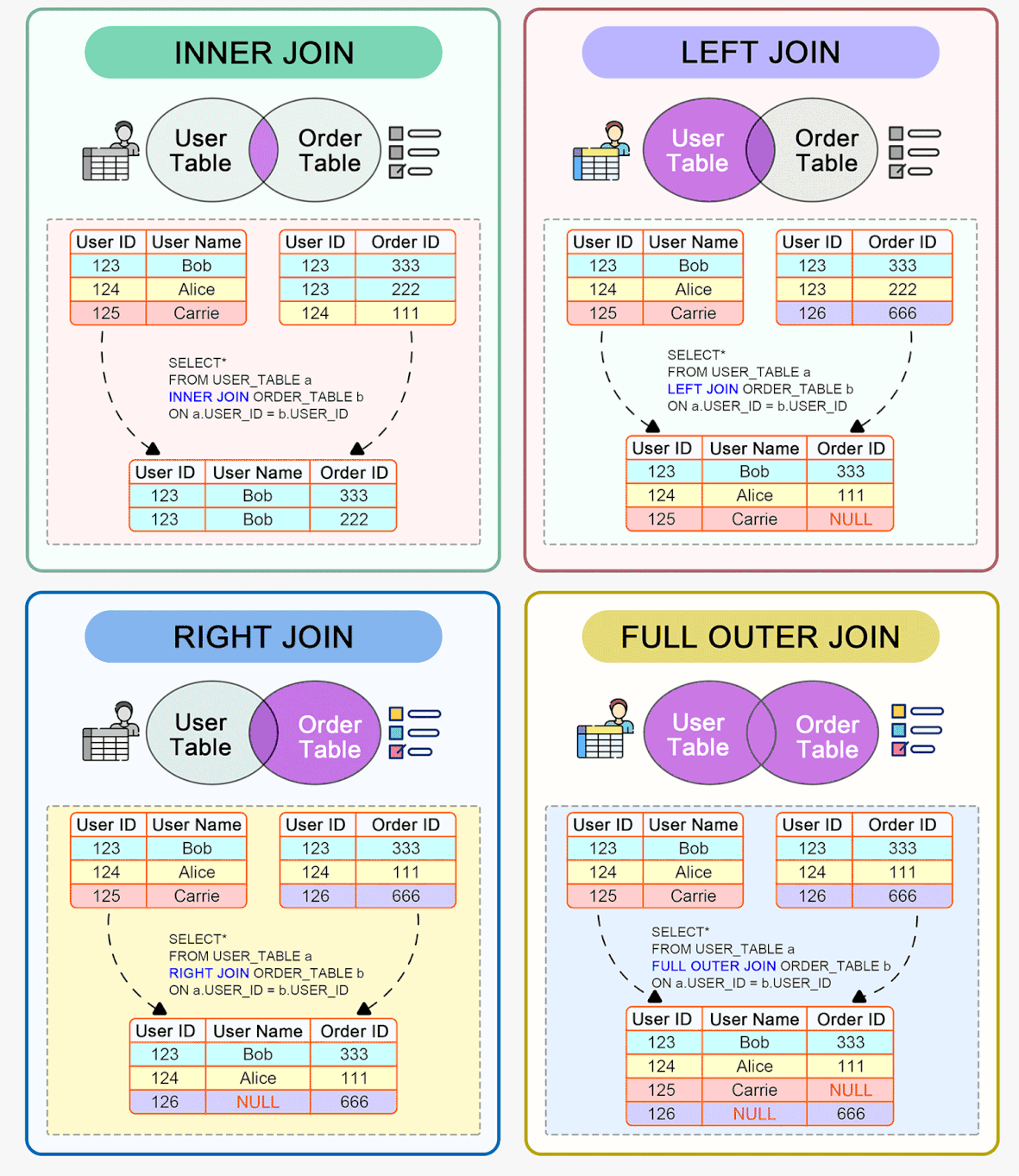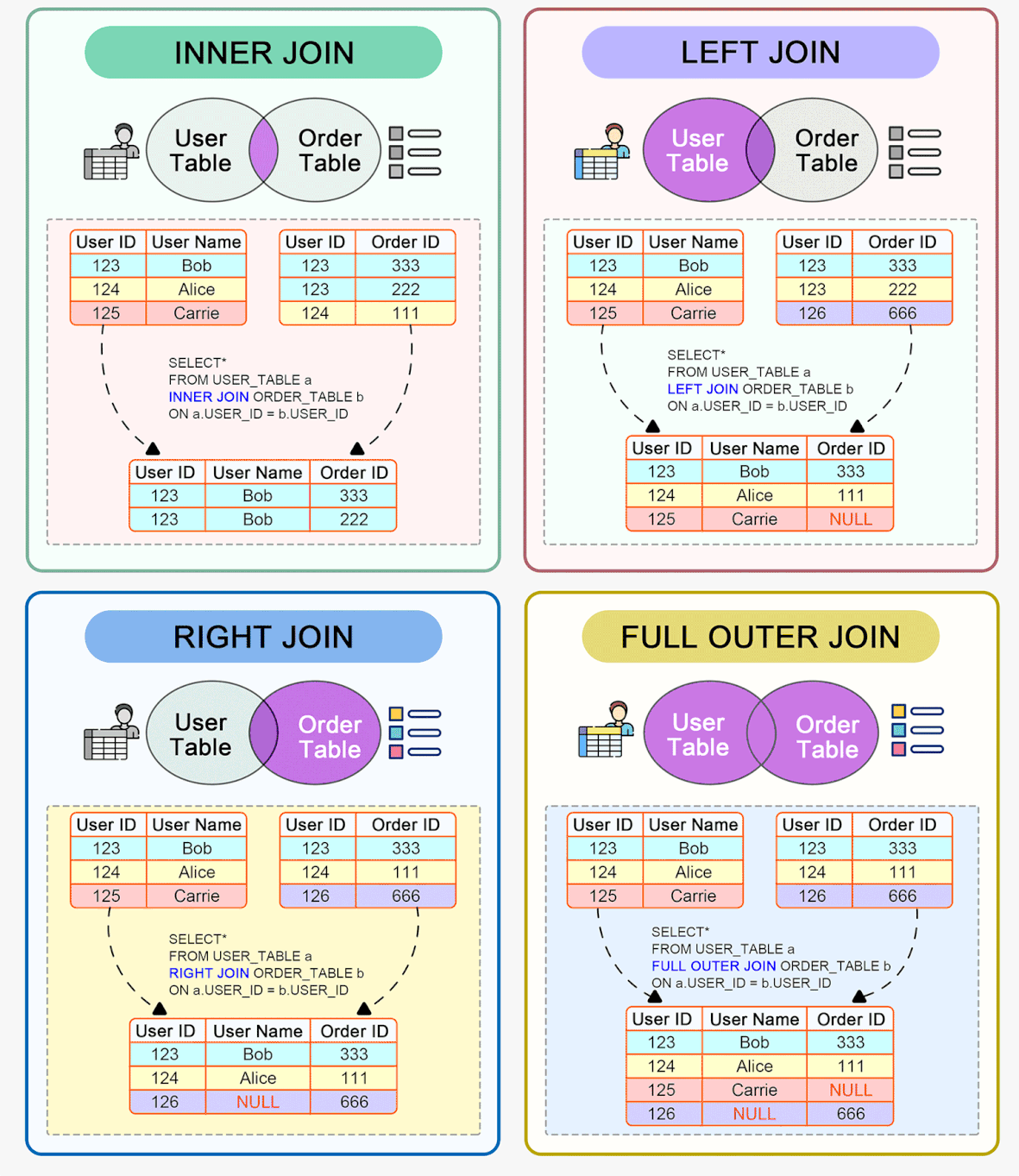
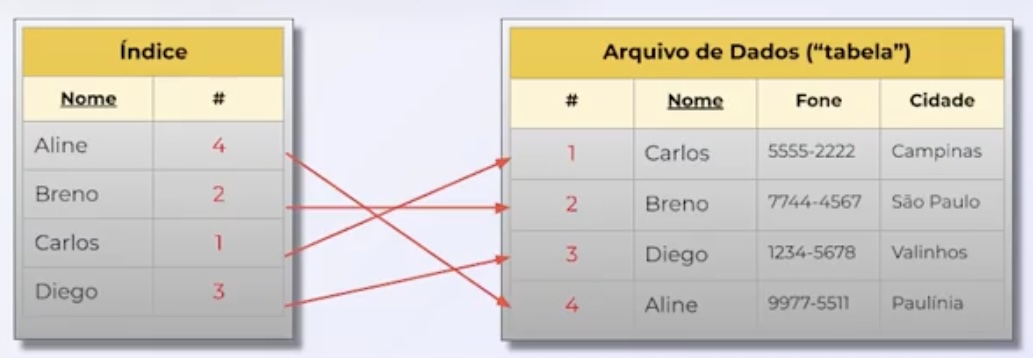
Índices
Índices são estruturas associadas a tabelas em bancos de dados que permitem localizar dados de forma rápida e eficiente. Eles funcionam como um "índice remissivo" apontando para a localização dos dados nas tabelas.
Existem diferentes tipos de índices como índices primários, secundários, únicos, compostos, clusterizados, não clusterizados etc.
-
O índice primário, também conhecido como primary key, é exclusivo para cada registro e normalmente utiliza um campo ou combinação de campos que identificam unicamente cada registro. Ele é utilizado para impor a integridade referencial entre tabelas.
-
Índices secundários, também chamados de alternate keys, podem conter campos duplicados e são utilizados para melhorar o desempenho em consultas que filtrem por estes campos.
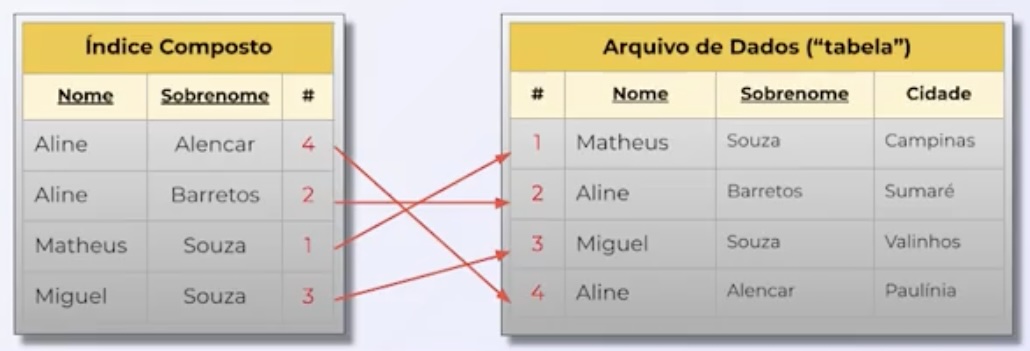
-
Um índice composto contém múltiplos campos em sua definição. Isso melhora o desempenho em consultas com filtros em vários campos. Porém tem algumas desvantagens como aumento no espaço utilizado, overhead em inserções e atualizações, entre outras.


A criação de índices deve ser feita com critério, avaliando o custo benefício para cada caso. Deve-se analisar os padrões de acesso aos dados, os campos mais utilizados em filtros e joins, o nível de seletividade dos campos etc.
Índices desnecessários ou em excesso podem até degradar o desempenho, portanto seu uso deve ser otimizado. Menos às vezes é mais quando o assunto é índice em bancos de dados.
Modelagem de Dados
Nesse site você encontra vários exemplos de modelagem de banco de dados.
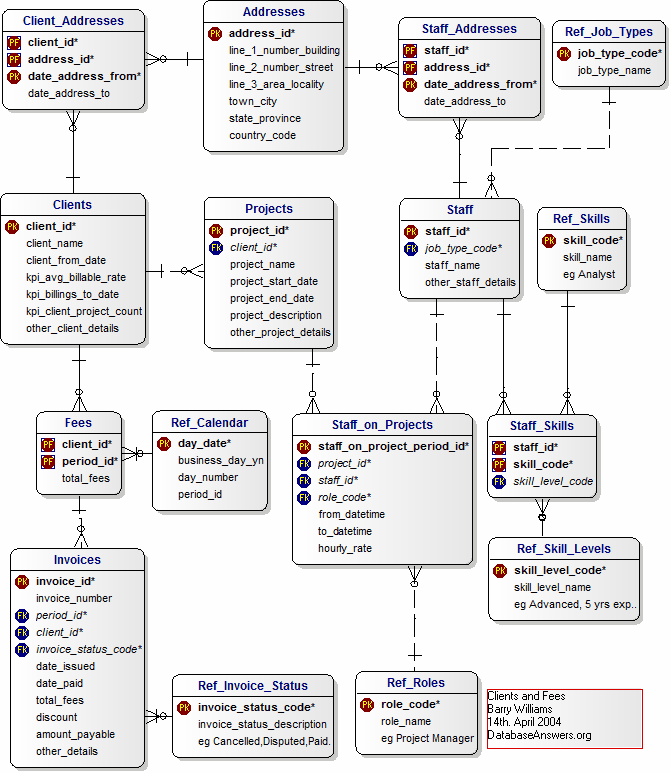
Diagrama de Classes UML
Útil para mapear objetos e seus relacionamentos. Integrável com bancos ORM.
Bancos Relacionais
Um Banco de Dados Relacional é um banco de dados que modela os dados em forma de campos e tabelas com relacionamento e integridade entre as tabelas. É controlado por um Sistema Gerenciador de Banco de Dados Relacional (SGBDR) - Relational Database Management System (RDBMS).
Representa tabelas, colunas, chaves e relacionamentos usando registros e chaves primárias/estrangeiras para relacionar dados. Mais próximo da implementação. Esquema e estrutura de dados pré-definidos. Excelente para queries estruturadas e transações ACID (Atomicidade, Consistência, Isolamento e Durabilidade). Exemplos: MySQL, PostgreSQL, SQL Server.
Vantagens:
- Estrutura de fácil entendimento Integridade referencial dos dados
- Dados (campos) estruturados
- Fácil manuseio (SQL)
Desvantagens:
- Necessita de conhecimento para criar modelagem
- Escalabilidade complexa
- Performance
- Escalabilidade Vertical (custo)
MySQL
O MySQL é um sistema gerenciador de banco de dados relacional (SGBDR) de código aberto muito popular. Algumas características principais do MySQL incluem:
-
Alto desempenho, velocidade e confiabilidade comprovadas para cargas de trabalho web e de servidor. Usado por muitos sites e aplicações de grande escala.
-
Suporte para grandes conjuntos de dados e alto volume de consultas. Boa escalabilidade com a capacidade de fragmentar dados entre servidores.
-
Tipos de dados flexíveis e fáceis de usar, como colunas JSON. Funções para análise e manipulação de documentos JSON.
-
Uma ampla gama de mecanismos de armazenamento como InnoDB, MyISAM etc., para diferentes casos de uso.
-
Métodos de acesso a dados SQL e NoSQL.
-
Segurança sólida de dados, incluindo conexões SSL, gerenciamento de usuários, controle de acesso.
-
Suporte multiplataforma para Linux, Windows, Mac e outros. Fácil migração entre plataformas.
-
Recursos de alta disponibilidade como replicação mestre-escravo, topologias de cluster.
-
Ferramentas de ajuste fornecidas para ajustar e otimizar o desempenho do banco de dados.
-
Extenso ecossistema de ferramentas GUI, monitoramento, soluções de backup, etc.
Algumas limitações do MySQL incluem:
-
Menor suporte transacional avançado e mecanismos de integridade em comparação com bancos de dados como PostgreSQL.
-
Não otimizado para cargas de trabalho analíticas mais avançadas em comparação com bancos de dados colunares.
-
Menos flexibilidade nas alterações do schema do banco de dados, exigindo mais tempo de inatividade para manutenção.
No geral, o MySQL se destaca em aplicativos web de alto desempenho. Oferece uma ótima combinação de velocidade, escalabilidade, recursos e facilidade de uso para cargas de trabalho CRUD padrão.
MariaDB
O MariaDB é um fork de código aberto do MySQL focado em performance e estabilidade. Principais características:
- Maior velocidade que o MySQL em benchmarks.
- Armazenamento de colunas para queries mais rápidas.
- Melhor utilização de núcleos e threads modernos.
- Compatível com aplicações MySQL existentes.
Bancos não Relacionais
Armazenam dados em documentos flexíveis como JSON ao invés de tabelas rigidamente estruturadas. Exemplos: MongoDB, DynamoDB, Cassandra;
Vantagens:
- Schema flexível ou inexistente; • Chave/Valor (Key/Value) • Orientado a Grafos • Orientado a Documentos • Armazenamento em Colunas
- Suporta mudanças frequentes;
- Foco em alta performance, escalabilidade e disponibilidade distribuída.
Desvantagens:
- Baixa consistência;
- Baixa Integridade;
- Necessita de conhecimento sobre os tipos de banco de dados existentes;
MongoDB
O MongoDB é um banco de dados NoSQL orientado a documentos muito popular para uso com Node.js. Algumas de suas principais características e aplicações com Node.js incluem:
-
Armazenamento de dados no formato JSON - Os documentos MongoDB armazenam dados em formato JSON, o que os torna muito fáceis de usar com aplicativos JavaScript como Node.js. Não é necessária nenhuma conversão de objetos.
-
Schema flexível - O MongoDB é schema-less, o que permite que os dados em um aplicativo possam ser facilmente alterados e evoluídos sem precisar modificar todo o banco de dados. Isso facilita o desenvolvimento ágil.
-
Alta performance - O MongoDB foi projetado para escalar horizontalmente em clusters para lidar com grandes volumes de dados e cargas pesadas. Ele se integra bem com o modelo assíncrono e orientado a eventos do Node.js.
-
Índices Ad-Hoc - Índices podem ser adicionados dinamicamente para melhorar o desempenho das consultas, útil para dados altamente variáveis.
-
Integração - Bibliotecas populares como Mongoose fornecem integração fácil entre Node.js e MongoDB para modelagem de dados e interações com o banco de dados.
Alguns pontos negativos incluem:
-
Menos consistência de dados - O MongoDB sacrifica alguma consistência de dados em favor da alta disponibilidade e desempenho. Pode ser um problema para alguns casos de uso.
-
Complexidade da modelagem de dados - Modelar dados corretamente com documentos e coleções complexas exige experiência. É menos intuitivo que bancos SQL relacionais.
-
Menos recursos de consulta - As opções de consulta e agregação de dados são mais limitadas que em bancos SQL, embora esta lacuna esteja diminuindo nas versões mais recentes.
O MongoDB 4.0 trouxe melhorias significativas como:
- Transações multi-documentos ACID.
- Balanceamento de carga entre shards.
- Compressão de dados WiredTiger.
- Motor de armazenamento em disco cifrado.
- Isso diminui algumas das desvantagens citadas anteriormente.
Bancos de Dados focados em Serverless
Dynamo
O DynamoDB possui:
- Backup e restore automático entre regiões.
- Criptografia em repouso e em trânsito.
- Cache em memória para performance.
FaunaDB
O FaunaDB também possui características interessantes:
- Transações ACID completas para garantir consistência e confiabilidade.
- Streaming de dados para processamento em tempo real.
- Inteligência de distribuição de dados entre regiões.
- Usa o Fauna Query Language (FQL) - Linguagem para Queries Fauna
Supabase
O Supabase é uma alternativa open source para o Firebase que provê funcionalidades como autenticação, armazenamento de dados e funções serverless para aplicações web e mobile.
Algumas vantagens importantes:
- Baseado em ferramentas sólidas e testadas como Postgres, Auth0 e Storage buckets S3.
- Interface dashboard intuitiva para gerenciar dados e usuários.
- API RESTful automatizada para CRUD.
- Bibliotecas cliente para dart, flutter, javascript, typescript etc.
- Foco em segurança e privacidade de dados.
- Preços competitivos e transparentes. O Supabase fornece uma ótima maneira de fazer prototipação e construir MVPs com back-end, autenticação e banco de dados já integrados. Também pode ser usado em produção para casos de uso menos complexos.
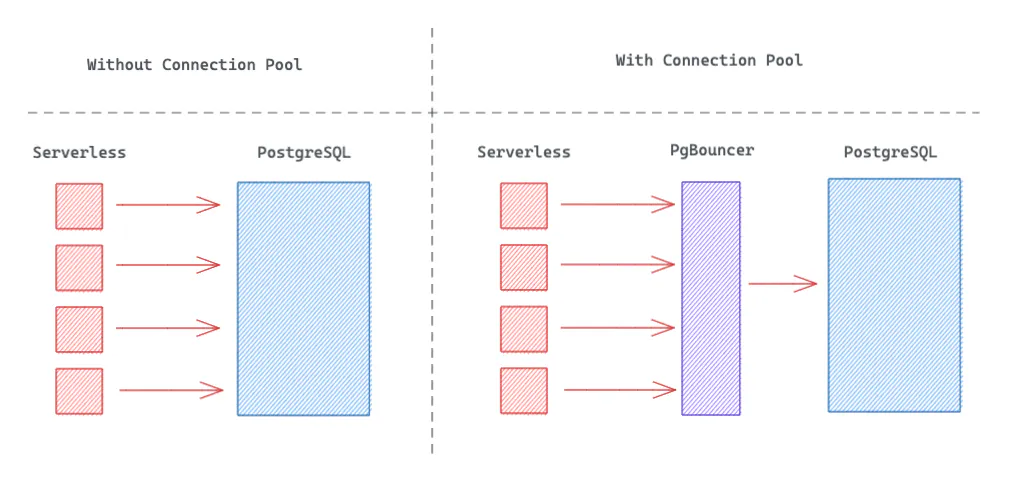
Supabase usa PgBouncer para pool de conexões. Um "pool de conexões" é um sistema (externo ao Postgres) que gerencia conexões, em vez do sistema nativo do PostgreSQL.
Quando um cliente faz uma solicitação, o PgBouncer “aloca” uma conexão disponível para o cliente. Quando a transação ou sessão do cliente é concluída, a conexão é retornada ao pool e fica livre para ser usada por outro cliente.
ORMs
Um ORM (Object-Relational Mapping) é uma técnica de desenvolvimento que faz um mapeamento entre um banco de dados relacional tradicional e uma representação de objetos compatível com a linguagem de programação utilizada.
Alguns benefícios dos ORMs:
- Abstrai e facilita o acesso ao banco de dados mapeando tabelas para classes e registros para objetos.
- Aumenta a produtividade ao reduzir quantidade de código de acesso a dados que precisa ser escrito.
- Adiciona recursos como lazy loading, caching, eager loading para melhorar performance.
Prisma:
- ORM moderno, type-safe e intuitivo para Node.js e TypeScript.
- Gera interfaces GraphQL para apps front-end.
- Migrações e seeds de banco de dados.
- Suporta PostgreSQL, MySQL, SQL Server, SQLite etc.
TypeORM:
- ORM para TypeScript e JavaScript para Node.js e browsers.
- Ênfase em performance, validação de entidades e migrations.
- Suporta diversos bancos de dados.
- Código e documentação muito completos.
Sequelize: ORM para Node.js que suporta PostgreSQL, MySQL, MariaDB, SQLite e MSSQL.
Hibernate: Popular ORM Java que suporta diversos bancos relacionais.