Databases


SQL
Stored Procedure, which translated means Stored Procedure, is a set of SQL commands that can be executed at once, as in a function. It stores repetitive tasks and accepts input parameters so that the task can be performed according to individual need.
A Stored Procedure can reduce network traffic, improve database performance, create scheduled tasks, reduce risks, create processing routines, etc.
For all these and other functions, stored procedures are extremely important for DBAs and developers.
There are some basic types of procedures we can create:
-
Local Procedures - Are created from a database in the user's own database;
-
Temporary Procedures - There are two types of temporary procedures: Locals, which must start with # and Globals, which must start with ##;
-
System Procedures - Stored in the SQL Server standard database (Master), we can identify them with the acronyms sp, which originates from stored procedure. Such procedures perform administrative tasks and can be executed from any database.
-
Remote Procedures - We can use Distributed Queries for such procedures. They are used only for compatibility.
-
Extended Procedures - Unlike the procedures already mentioned, this type of procedure receives the .dll extension and is executed outside the SQL Server DBMS. They are identified with the xp prefix.
-
CLR (Common Language Runtime) procedures - allow .NET code to be incorporated into SQL procedures.
Data Base Management System or System (DBMS)
Data Base Management System or Database Management System (DBMS) is a set of software used to manage a database, responsible for controlling, accessing, organizing and protecting the information in an application, with the main objective to manage the databases used by client applications and remove this responsibility from them.
There are several DBMSs that use SQL, such as Oracle, MySQL, PostgreSQL, SQL Server, etc. Each with its own particularities.
The ANSI SQL defines a standard language that allows greater portability between DBMSs.
Here is the translation:
DDL AND DML
DDL and DML are types of SQL language.
-
DDL: Data Definition Language, despite the name does not interact with the data itself but with the database objects.
-
Commands of this type are CREATE, ALTER and DROP.
-
DML: Data Manipulation Language, interacts directly with the data inside the tables.
-
DML commands are INSERT, UPDATE and DELETE.
-- List Tables: adding \G at the end lists the result in rows
SHOW TABLES;
-- LIMIT OFFSET COUNT
SELECT * FROM plays LIMIT 10 OFFSET 0;
SELECT plays.id, plays.title, SUM(COALESCE(reservations.number_of_tickets,0))
FROM plays
INNER JOIN reservations ON plays.id=reservations.play_id
GROUP BY plays.id, plays.title
ORDER BY reservations.number_of_tickets ASC, PLAYS.ID DESC
LIMIT 5 OFFSET 10;
-- Delete Row
DELETE FROM table_name WHERE condition;
DELETE FROM TIPO_FORMA_PAGAMENTO
WHERE ID_FORMA_PAG IN (12, 13, 14);
-- Delete Table
DROP TABLE table_name;
DROP TABLE employees;
-- Delete table data
DELETE FROM employees;
TRUNCATE TABLE employees;
-- Describe table data
DESCRIBE table_name;
DESCRIBE employees;
-- Unlock foreign key
-- You can disable and re-enable the foreign key constraints
-- before and after deleting
ALTER TABLE CONTABANCO_MOV NOCHECK CONSTRAINT ALL;
DELETE FROM MyTable;
ALTER TABLE MyOtherTable CHECK CONSTRAINT ALL;
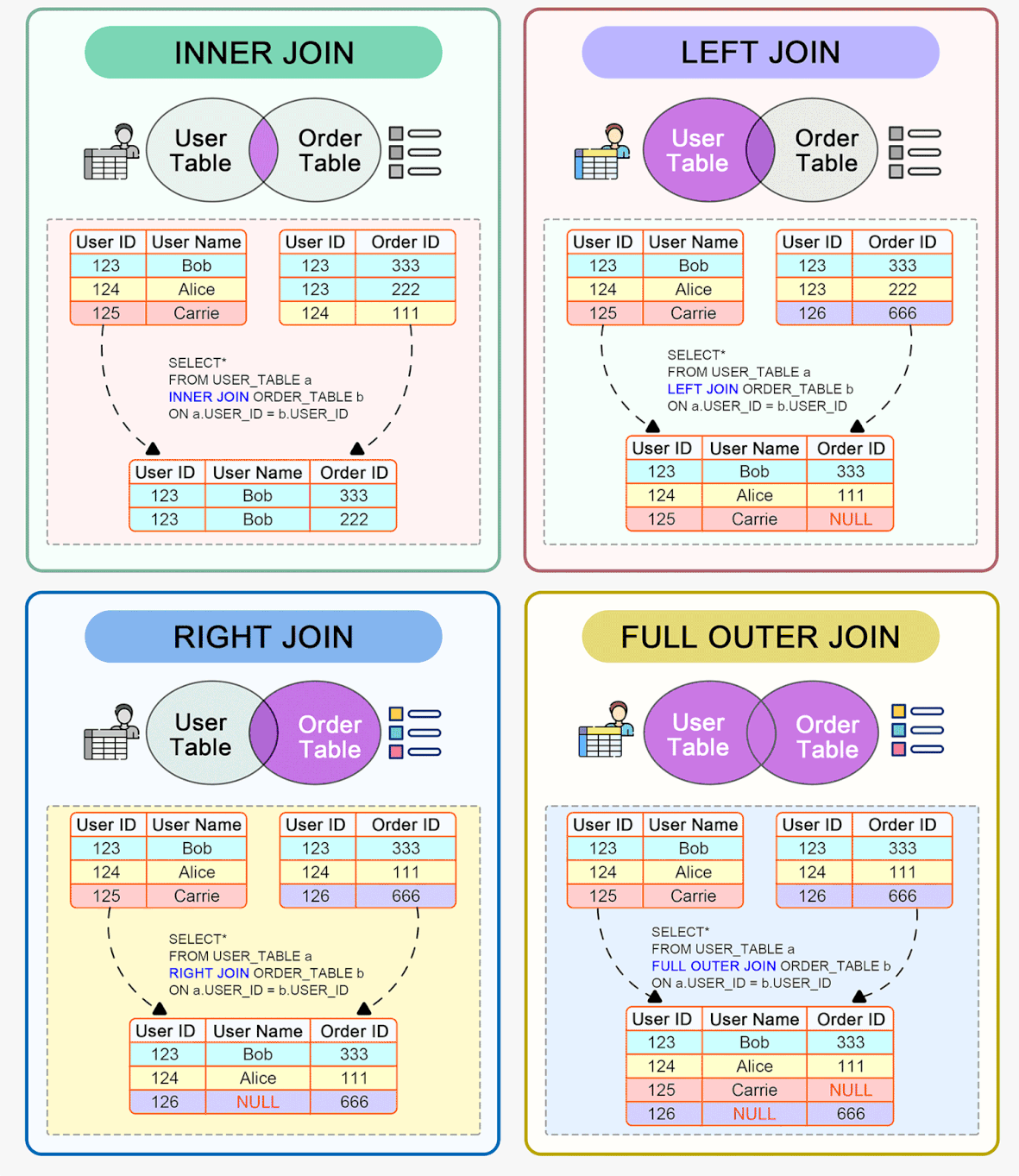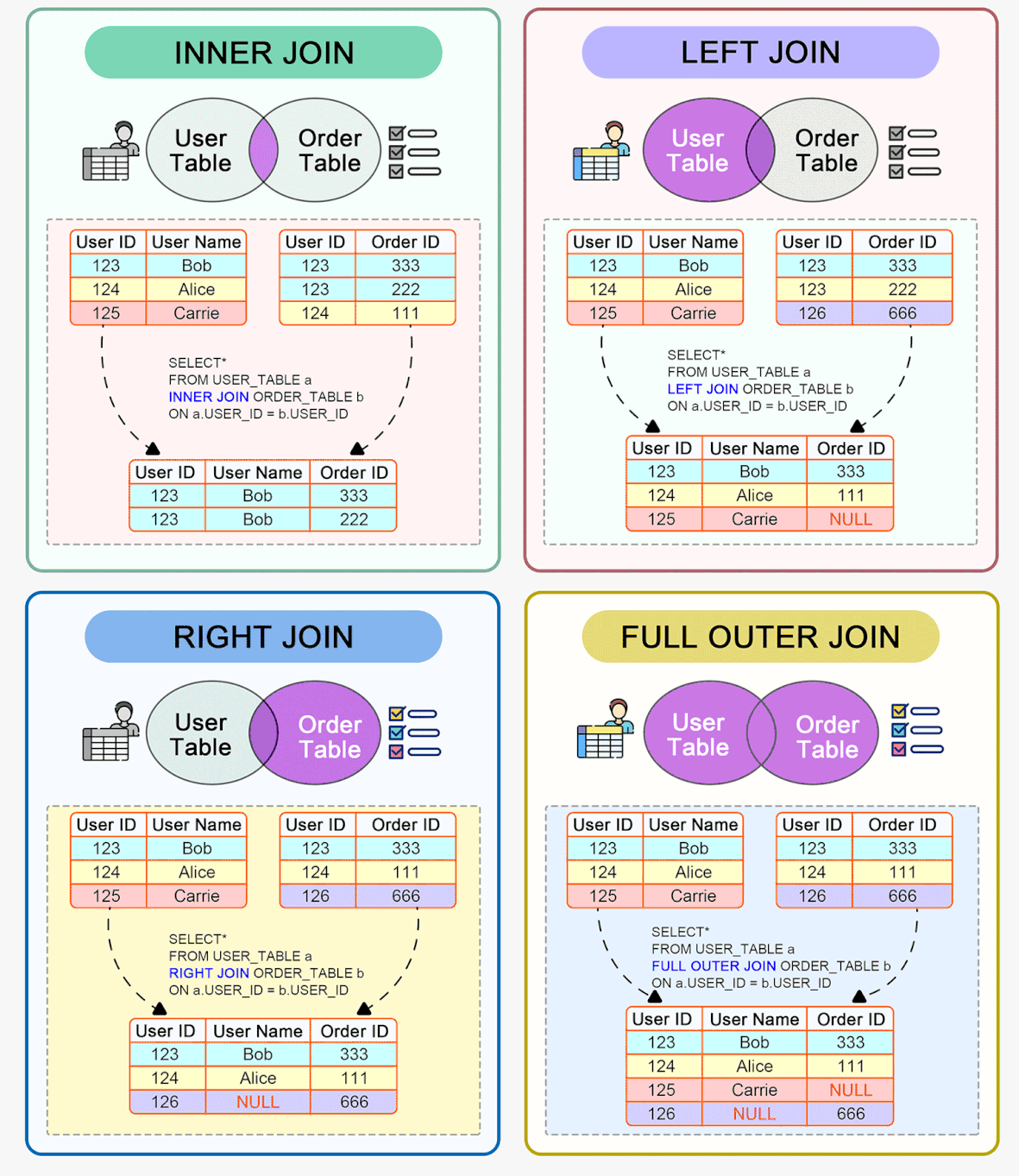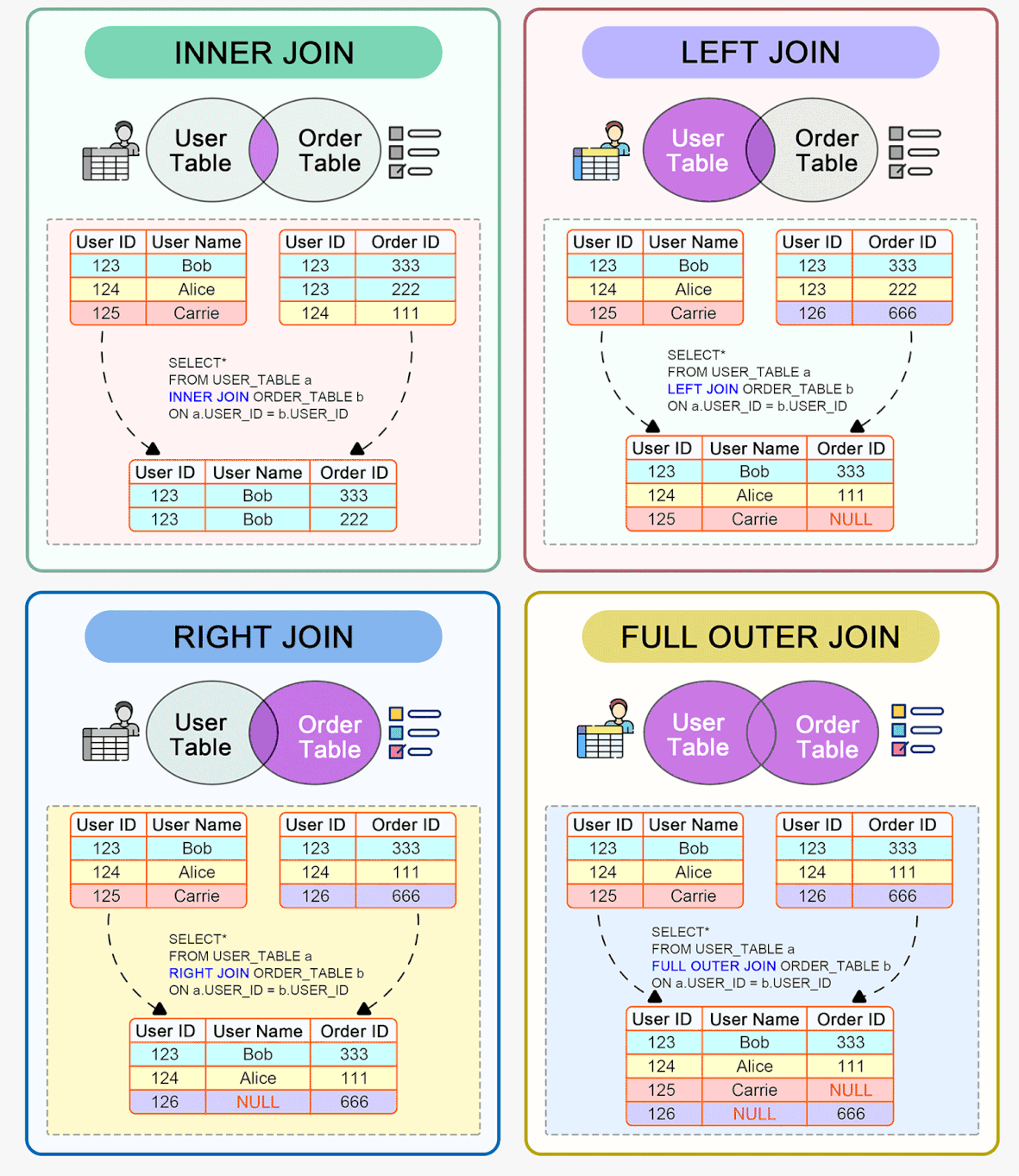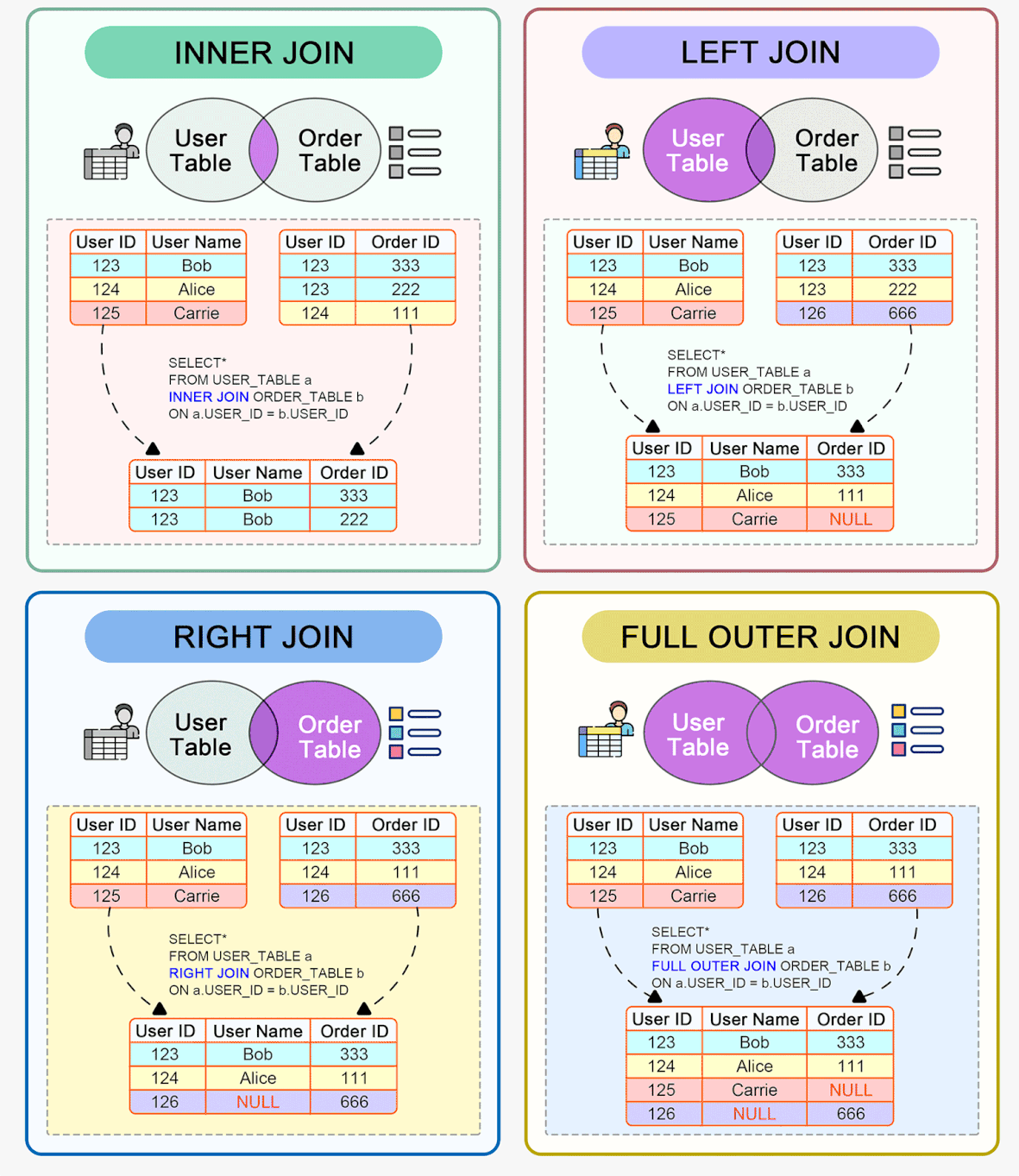
Indexes
Indexes are structures associated with database tables that allow locating data quickly and efficiently. They work like a "back-of-the-book index" pointing to the location of the data in the tables.
There are different types of indexes such as primary, secondary, unique, composite, clustered, nonclustered etc.
- The primary index, also known as the primary key, is exclusive to each record and usually uses one field or a combination of fields that uniquely identify each record. It is used to enforce referential integrity between tables.
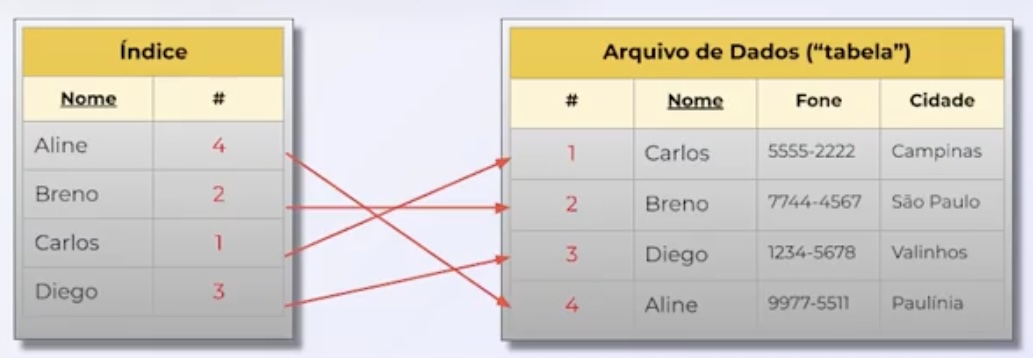
- Secondary indexes, also called alternate keys, can contain duplicate fields and are used to improve performance in queries filtered by these fields.
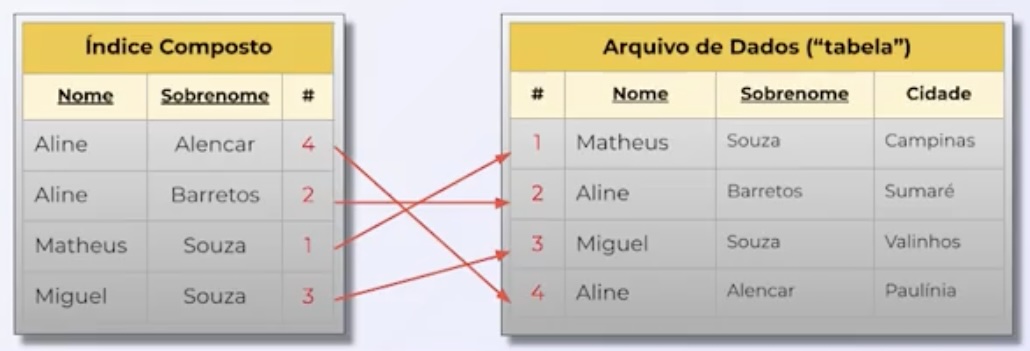
- A composite index contains multiple fields in its definition. This improves performance in queries with filters on multiple fields. However, it has some disadvantages such as increased space usage, overhead on inserts and updates, among others.
The creation of indexes must be done with criteria, evaluating the cost benefit for each case. Access patterns to data, fields most used in filters and joins, selectivity level of fields etc. must be analyzed.
Unnecessary or excessive indexes can even degrade performance, so their use must be optimized. Less is sometimes more when it comes to database indexing.
Data Modeling
On this site you can find several examples of database modeling.
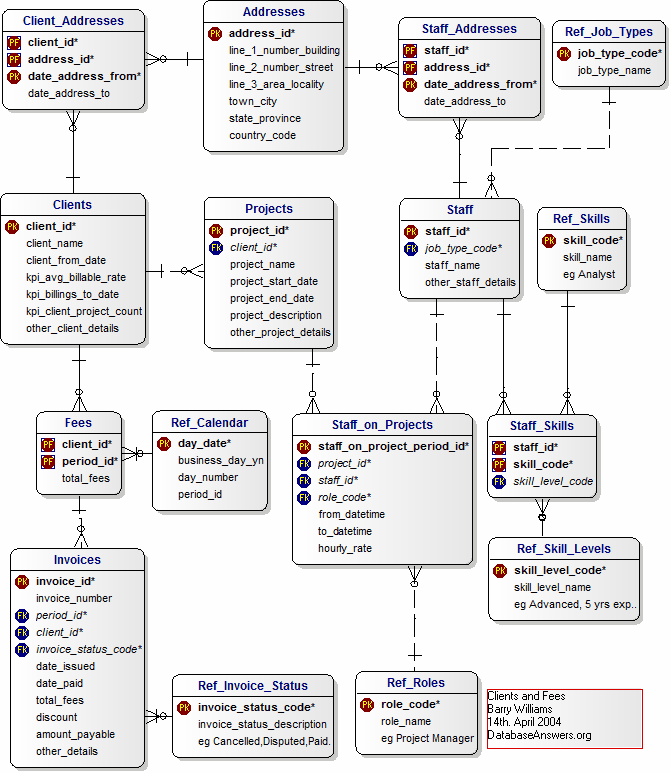
UML Class Diagram
Useful for mapping objects and their relationships. Integratable with ORM databases.
Relational Databases
A Relational Database is a database that models data in the form of fields and tables with relationships and integrity between the tables. It is controlled by a Relational Database Management System (RDBMS).
It represents tables, columns, keys and relationships using records and primary / foreign keys to relate data. Closer to implementation. Predefined schema and data structure. Excellent for structured queries and ACID transactions (Atomicity, Consistency, Isolation and Durability). Examples: MySQL, PostgreSQL, SQL Server.
Advantages:
- Easy to understand structure
- Referential integrity of data
- Structured data (fields)
- Easy to handle (SQL)
Disadvantages:
- Requires knowledge to create modeling
- Complex scalability
- Performance
- Vertical Scalability (cost)
MySQL
MySQL is a very popular open source relational database management system (RDBMS). Some key features of MySQL include:
- High performance, proven speed and reliability for web and server workloads. Used by many large-scale websites and applications.
- Support for large datasets and high volume of queries. Good scalability with the ability to shard data across servers.
- Flexible and easy to use data types like JSON columns. Functions for parsing and manipulating JSON documents.
- A wide range of storage engines like InnoDB, MyISAM etc catering to different use cases.
- SQL and NoSQL type access methods to data.
- Strong data security including SSL connections, user management, access control.
- Cross platform support for Linux, Windows, Mac and others. Easy migration across platforms.
- High availability features like master-slave replication, cluster topologies.
- Tuning tools provided to tweak and optimize database performance.
- Extensive ecosystem of GUI tools, monitoring, backup solutions etc.
Some limitations of MySQL include:
- Less advanced transactional support and integrity mechanisms compared to databases like PostgreSQL.
- Not optimized for more advanced analytical workloads compared to columnar databases.
- Less flexibility in database schema changes requiring more maintenance downtime.
Overall, MySQL excels in high performance web-based applications. It offers a great combination of speed, scalability, features and ease of use for standard CRUD based workloads.
MariaDB
MariaDB is an open source fork of MySQL focused on performance and stability. Main features:
- Faster than MySQL in benchmarks.
- Columnar storage for faster queries.
- Better use of modern cores and threads.
- Compatible with existing MySQL applications.
Non-Relational Databases
They store data in flexible documents like JSON instead of rigidly structured tables.
Examples: MongoDB, DynamoDB, Cassandra;
Advantages:
- Flexible or nonexistent schema;
• Key / Value
• Graph Oriented • Document Oriented
• Column Storage - Supports frequent changes;
- Focus on high performance, scalability and distributed availability.
Disadvantages:
- Low consistency;
- Low Integrity;
- Need for knowledge about existing database types;
MongoDB
MongoDB is a very popular document oriented NoSQL database for use with Node.js. Some of its key features and applications with Node.js include:
-
JSON data storage - MongoDB documents store data in JSON format, making them very easy to use with JavaScript applications like Node.js. No object conversion is required.
-
Flexible schema - MongoDB is schema-less, allowing application data to be easily changed and evolved without needing to modify the entire database. This facilitates agile development.
-
High performance - MongoDB was designed to scale horizontally in clusters to handle large volumes of data and heavy loads. It integrates well with Node.js's asynchronous, event-driven model.
-
Ad-Hoc Indexes - Indexes can be dynamically added to improve query performance, useful for highly variable data.
-
Integration - Popular libraries like Mongoose provide easy integration between Node.js and MongoDB for data modeling and database interactions.
Some negatives include:
-
Less data consistency - MongoDB sacrifices some data consistency in favor of high availability and performance. Can be an issue for some use cases.
-
Data modeling complexity - Properly modeling data with complex documents and collections requires experience. It is less intuitive than relational SQL databases.
-
Fewer query features - Query and data aggregation options are more limited than in SQL databases, although this gap is narrowing in later versions.
MongoDB 4.0 brought significant improvements such as:
- Multi-document ACID transactions.
- Load balancing between shards.
- WiredTiger data compression.
- Encrypted disk storage engine.
Databases focused on Serverless
Dynamo
DynamoDB has:
- Automatic backup and restore between regions.
- Encryption at rest and in transit.
- In-memory caching for performance.
FaunaDB
FaunaDB also has interesting features:
- Full ACID transactions to ensure consistency and reliability.
- Data streaming for real-time processing.
- Intelligent data distribution between regions.
- Uses the Fauna Query Language (FQL)
Supabase
Supabase is an open source alternative to Firebase that provides features like authentication, data storage and serverless functions for web and mobile applications.
Some important advantages:
- Based on proven, tested tools like Postgres, Auth0 and S3 storage buckets.
- Intuitive dashboard interface to manage data and users.
- Automated CRUD RESTful API.
- Client libraries for dart, flutter, javascript, typescript etc.
- Focus on data security and privacy.
- Competitive and transparent pricing.
Supabase provides a great way to prototype and build MVPs with back-end, authentication and database already integrated. It can also be used in production for less complex use cases.
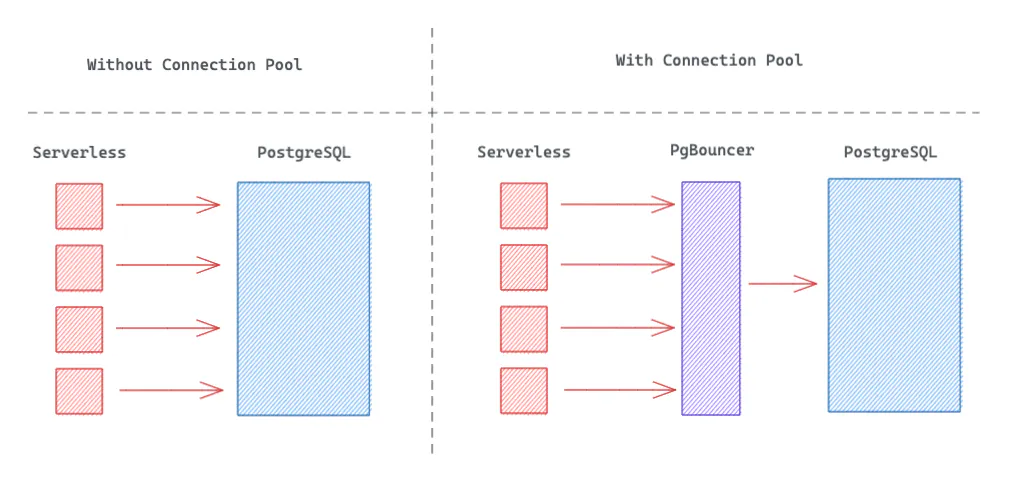
Supabase uses PgBouncer for connection pooling. A "connection pool" is a system (external to Postgres) that manages connections, instead of PostgreSQL's native system.
Here is the translation of that part:
When a client makes a request, PgBouncer "allocates" an available connection to the client. When the client's transaction or session is completed, the connection is returned to the pool and becomes free to be used by another client.
ORMs
An ORM (Object-Relational Mapping) is a development technique that maps between a traditional relational database and an object representation compatible with the programming language used.
Some benefits of ORMs:
- Abstracts and facilitates database access by mapping tables to classes and records to objects.
- Increases productivity by reducing the amount of data access code that needs to be written.
- Adds features like lazy loading, caching, eager loading to improve performance.
Prisma:
- Modern, type-safe and intuitive ORM for Node.js and TypeScript.
- Generates GraphQL interfaces for front-end apps.
- Database migrations and seeds.
- Supports PostgreSQL, MySQL, SQL Server, SQLite etc.
Resources: Migration: https://echobind.com/post/make-prisma-ignore-a-migration-change
TypeORM:
- ORM for TypeScript and JavaScript for Node.js and browsers.
- Emphasis on entity validation and migrations performance.
- Supports various databases.
- Very complete code and documentation.
Sequelize:
Node.js ORM that supports PostgreSQL, MySQL, MariaDB, SQLite and MSSQL.
Hibernate:
Popular Java ORM that supports various relational databases.

Performance
Pagination
Traditional pagination using OFFSET seems simple at first:
SELECT * FROM posts
ORDER BY created_at DESC
OFFSET 20 LIMIT 10;
However, this approach has two major problems:
-
Performance Issues: The database must fetch and discard all rows before your offset. If you're on page 100, it processes 1000 rows just to show 10!
-
Data Inconsistency: Consider this scenario:
- User loads page 1 (rows 1-10)
- New post is created
- User loads page 2 (rows 11-20)
- The new post has pushed everything down, causing either:
- Duplicate content
- Skipped content
Enter Keyset Pagination
Keyset pagination (also called cursor-based pagination) solves these issues by using the values from the last item to fetch the next page:
SELECT * FROM posts
WHERE created_at < :last_seen_timestamp
ORDER BY created_at DESC
LIMIT 10;
Benefits
- Better Performance: No wasted processing of skipped rows
- Consistency: New items don't affect pagination
- Perfect for Infinite Scroll: Natural fit for "Load More" functionality
Limitations
- No Random Page Access: Can't jump directly to page 50
- More Complex Implementation: Requires tracking position markers
- Multiple Sort Columns: Gets more complex with compound sorting
Best Use Cases
- Social media feeds
- Infinite scroll implementations
- Real-time data streams
- Large dataset navigation
Safe Column Removal in Production
Dropping a database column in a production environment with rolling deploys requires careful coordination. Many ORMs (like Django's ORM, Hibernate, Prisma) explicitly list every model field in SELECT, INSERT, and UPDATE queries. This means if you drop a column while old application servers are still running, those servers will fail with errors like UndefinedColumn: column does not exist.
The Problem
In a rolling deploy:
- Database migrations run first
- Application servers update one at a time
- During this window, old-code servers coexist with the already-migrated database
If a migration drops a column, any old server still referencing that column will crash.
The Solution: 2-Deploy Column Removal
Deploy 1 — Stop querying the column
- Remove the field/column definition from the ORM model
- Remove all code references (serializers, queries, API responses)
- Do NOT create a migration — the column stays in the database
- Old servers still have the column in their queries, but that's fine — querying an existing column is harmless
Deploy 2 — Drop the column
- Create and run the migration that drops the column
- All servers have already stopped querying it since Deploy 1
Timeline:
Deploy 1 Deploy 2
(remove from ORM) (drop from DB)
| |
Old servers ──────────────| |
(query column) ✓ | |
| |
New servers ──────────────|────────────────────────|
(don't query column) ✓ | Column exists but | Column dropped ✓
| not queried ✓ |
Adding a Column Safely
The reverse problem: adding a NOT NULL column causes errors because old servers don't include it in INSERT statements.
- Always add new columns as
NULLfirst - Enforce required constraints at the application level
- In a follow-up deploy, backfill data and then add the
NOT NULLconstraint
Renaming a Column (3 Deploys)
Renaming is the most dangerous — it combines a remove and an add:
- Deploy 1: Add the new column as
NULL, write to both, read from new (fallback to old) - Deploy 2: Remove all references to the old column, remove it from the ORM model
- Deploy 3: Drop the old column via migration
ORM-Specific Notes
| ORM | Behavior | Key Detail |
|---|---|---|
| Django | Lists all model fields in queries | Remove field from models.py, defer makemigrations |
| Prisma | Schema-driven migrations | Use prisma migrate with --create-only to defer |
| Hibernate | Maps entity fields to columns | Remove from @Entity class, defer Flyway/Liquibase migration |
| TypeORM | Syncs entities to schema | Disable synchronize, manage migrations manually |
| Sequelize | Model defines query fields | Remove from model definition, create migration separately |
The key principle applies universally: decouple the code change from the schema change, and deploy them in the right order.
Resources: https://use-the-index-luke.com/no-offset N+1 queries

