Hi, I'm Abílio Azevedo
Da programação aos produtos!









Documentos Técnicos
Aprenda a importância vital da documentação técnica abrangente para projetos de software em crescimento. Descubra as melhores práticas, como Requests for Comments (RFCs) e Architectural Decision Records (ADRs), que promovem transparência, colaboração e registro de decisões arquiteturais. Explore ferramentas poderosas como wiki.js e Backstage para criar centros de documentação eficazes. Mantenha seu projeto organizado, compreensível e sustentável com essa abordagem à documentação técnica.

Abílio Azevedo
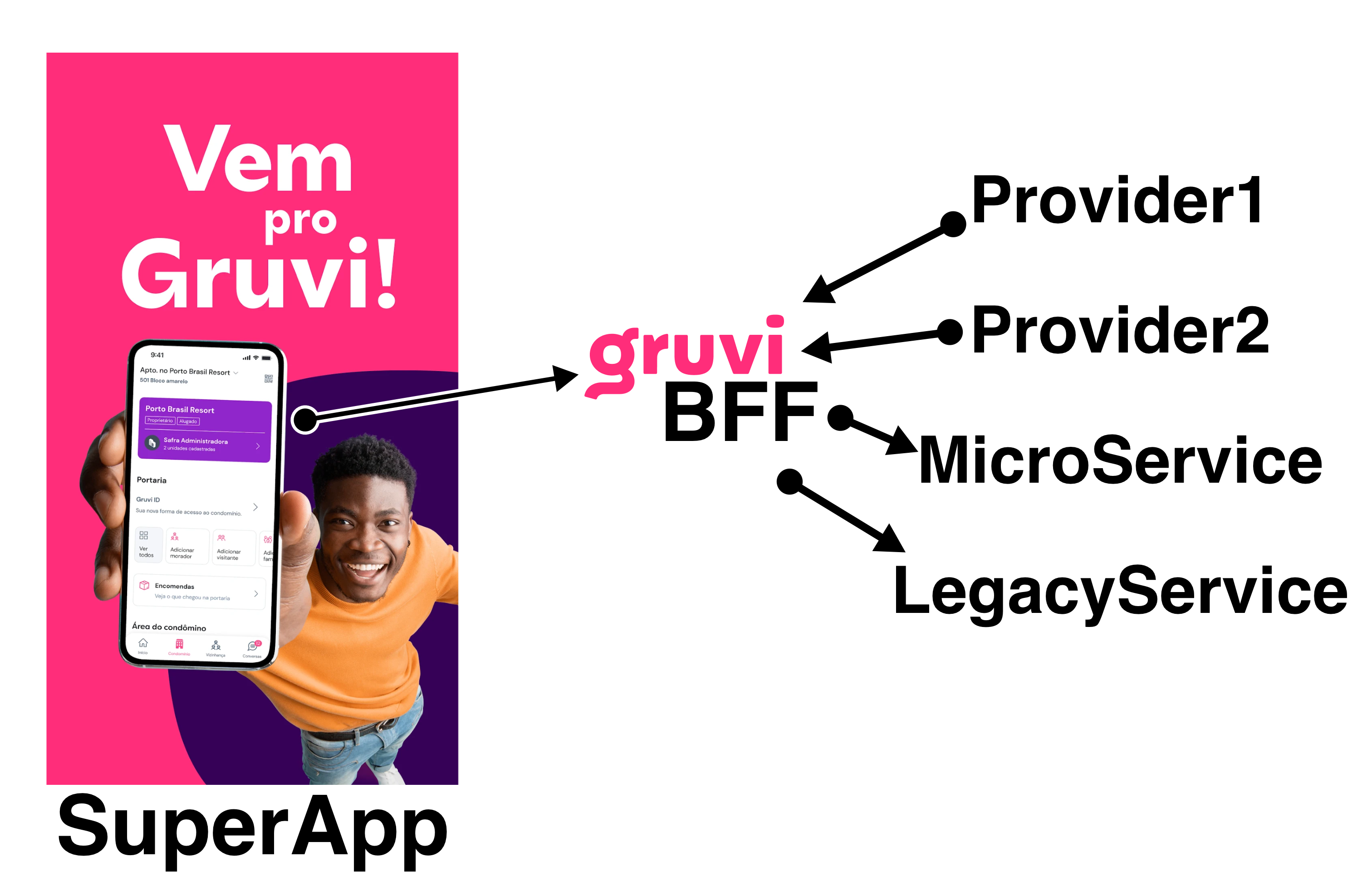
Superlógica - BFF para o Gruvi
Construindo um BFF (Backend for Frontend) para o SuperApp Gruvi que tem mais de 120 mil usuários ativos e milhões de possíveis usuários para disponibilizar no ecossistema Superlogica.
Abílio Azevedo